
Real-Time at Sea: Harnessing Data Stream Processing to Power Smarter Maritime Logistics
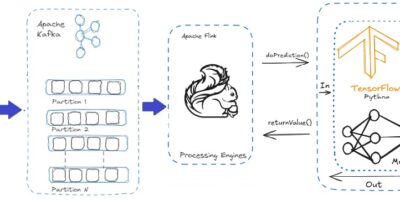
According to the International Chamber of Shipping, the maritime industry has increased fourfold in the last four decades. As the complexity of marine trade increases, ports and shipping companies need […]
{kind=link}
{kind=link}
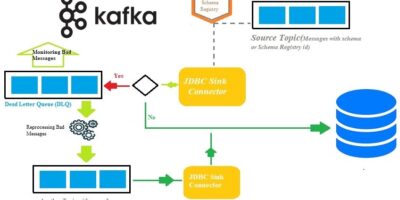
Handling bad messages via DLQ by configuring JDBC Kafka Sink Connector
Any trustworthy data streaming pipeline needs to be able to identify and handle faults. Exceptionally while IoT devices ingest endlessly critical data/events into permanent persistence storage like RDBMS for future […]
{kind=link}

{kind=link}

Resolve Apache Zookeeper starting issue installed on multi-node cluster
This miniature article explains how to resolve the error “Error: Could not find or load main class org.apache.zookeeper.server.quorum.QuorumPeerMain“ when we start the Apache Zookeeper (apache-zookeeper-3.5.6.tar.gz) installed on a multi-node cluster. […]
{kind=link}
Install and Configuration of Apache Hive-3.1.2 on multi-node Hadoop-3.2.0 cluster with MySQL for Hive metastore
The apache Hive is a data warehouse system built on top of the Apache Hadoop. Hive can be utilized for easy data summarization, ad-hoc queries, analysis of large datasets stores […]
{kind=link}
{kind=link}
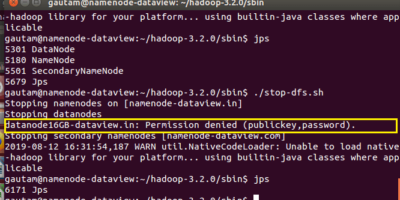
Resolve permission issue among DataNodes with NameNode to establish Secure Shell /SSH without passphrase
Sometimes it has been observed that when we configure and deploy multi-node Hadoop cluster or add new DataNodes, there is a SSH permission issue in communication with Hadoop daemons. In […]
{kind=link}
{kind=link}
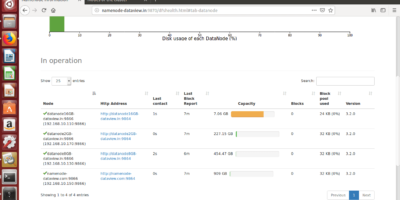
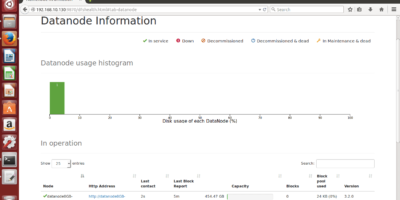
Manual procedure to add a new Datanode into an existing basic data lake without Apache Ambari or Cloudera Manager. Constructed using HDFS (Hadoop Distributed File System) on the multi-node cluster
The aim of this article is to highlight the essential steps when there would be a need for a new DataNode into an exiting multi-node Hadoop cluster. Midsize or startup […]