Installation of Apache Hadoop 3.2.0

Apache Hadoop 3.2.0 has been released after incorporating many outstanding enhancements over the previous stable release. The objective of this article is to explain step by step installation of Apache Hadoop 3.2.0 on OS Ubuntu 14.04 as a single node cluster. Here OpenJDK 11 is installed and configured as a java version. We can use this single node cluster to verify and understand better about the changes, newly incorporated features, enhancements and optimization. If there is an intension to set up a basic Data Lake using HDFS in multi node cluster, former can be beneficial to architect and design. However, other mandatory software components to support ingestion, data partitioning, data governance, security etc need to be integrated and evaluated separately. As this single node cluster will act as both master(NameNode) as well as slave(datanode), minimum 8 GB RAM of the system is preferable.
1. Prerequisites
(a) OpenJDK 11 Installation
To install Openjdk 11 in Ubuntu 14.04, here are the commands to execute in sequence from terminal if not logged
in as root
– Install Python Software Properties. can avoid if already installed earlier
$ sudo apt-get install python-software-properties
– Add repository
$ sudo add-apt-repository ppa:openjdk-r/ppa
– Update source list
$ sudo apt-get update
– Install OpenJDK 11 from source list
$ sudo apt install openjdk-11-jdk
– Update source list again
$ sudo apt-get update
– After installation of OpenJDK 11, below command to verify the installed version of Java
$ java -version

(b) Create Apache Hadoop 3.2.0 user (Optional)
We can create a normal (not root) account for Apache Hadoop 3.2.0 working. This will provide better transparency but optional and not mandatory. We can create an account by using the following command. Let’s say user name is hdadmin. If created for previous version of Hadoop then can continue with that user.
$ adduser hdadmin
$ passwd hdadmin
(c) SSH configuration and other utilities
– Install Open SSH Server-Client (If not installed earlier for previous version of Hadoop)
$sudo apt-get install openssh-server openssh-client
– Generate Key Pairs
$ su – hdadmin
$ ssh-keygen -t rsa -P ” -f ~/.ssh/id_rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ chmod 0600 ~/.ssh/authorized_keys
– Check by ssh to localhost or IP of the system to make sure it is working fine.
$ ssh 192.168.10.130
2. Download Apache Hadoop 3.2.0 and install
– Apache Hadoop 3.2.0 can be downloaded from the below link
Click here to visit
– Untar Tar ball
$tar xzf hadoop-3.2.0.tar.gz
3. Hadoop Pseudo-Distributed Mode Setup
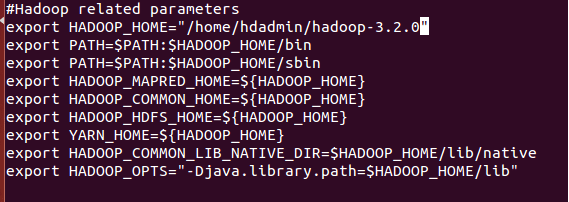
(a) Setup Hadoop Environment Variables
As a initial, set environment variables by editing ~/.bashrc file that uses by Hadoop daemons. And apply the changes in the current running environment
$ source ~/.bashrc
(b) Set JAVA_HOME in hadoop-env.sh
Edit $HADOOP_HOME/etc/hadoop/hadoop-env.sh file and set JAVA_HOME environment variable. Change the JAVA path as per installation of OpenJDK 11 on the system.

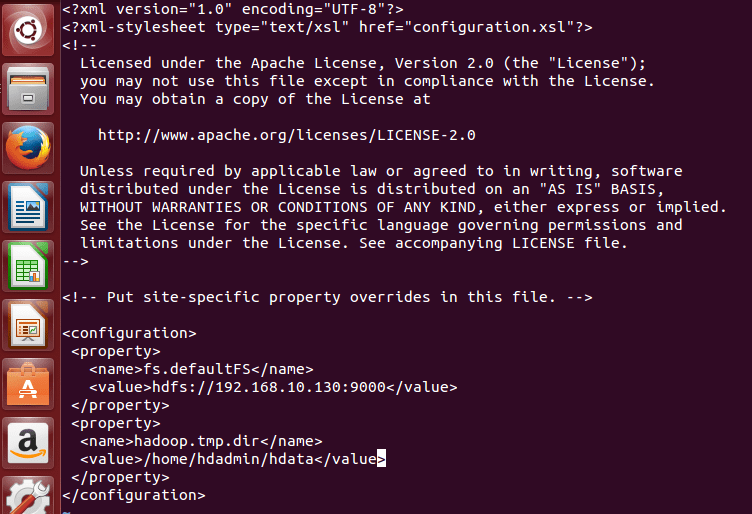
(c) Modify core-site.xml
Edit core-site.xml located in $HADOOP_HOME/etc/hadoop/ and add the following parameters. Value of 192.168.10.130 in hdfs://192.168.10.130:9000 has to be replaced with your IP address or localhost. hdfs://your IP address/localhost:9000. Also the path of directory for hadoop.tmp.dir
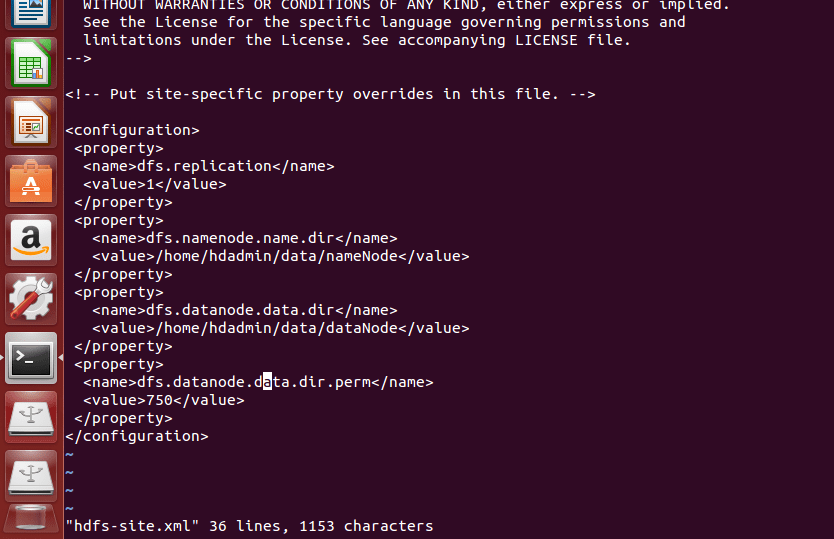
(d) Modify hdfs-site.xml
Edit hdfs-site.xml located in $HADOOP_HOME/etc/hadoop/ add the following parameters inside XML element ‘configuration’. Prior to that, create directories manually for dfs.nameNode.name.dir as well as dfs.dataNode.data.dir
(e) Edit mapred-site.xml
Add the following parameters in mapred-site.xml inside element ‘configuration’ located in $HADOOP_HOME/etc/hadoop/

(f) Edit yarn-site.xml
Add the following parameters in yarn-site.xml inside element ‘configuration’ located in $HADOOP_HOME/etc/hadoop/. The value for yarn.resourcemanager.hostname has to be replaced with your system IP address or localhost.

(g) Verify worker file
Make sure that the worker file available inside /hadoop-3.2.0/etc/hadoop already updated with localhost. localhost can be replaced with IP of the system or alias name if configured in /etc/hosts file. In multi-node Hadoop cluster, worker file in NameNode or Master Nodes holds the list of IP address/Alias names those belongs to Data Nodes in the cluster.
(h) Copy or download activation1.1.jar
Copy or download activation1.1.jar from older version of Hadoop or JDK and place inside Hadoop common lib directories (hadoop-3.2.0/share/hadoop/common/lib/, hadoop-3.2.0/share/hadoop/yarn/lib/, hadoop-3.2.0/share/hadoop/yarn/). OpenJDK 11 has not included activation1.1.jar in current release.
4. Format NameNode or Master node
We need to format the NameNode before starting the single node cluster using following command
$ hdfs namenode -format
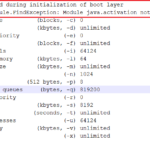
Following should appear for successful format of NameNode or Master node
![]()
5. Start the single node hadoop cluster
(a) Start HDFS Daemons
Start NameNode daemon and DataNode daemon by executing following command through terminal from /hadoop3.2.0/sbin/
$ ./start-dfs.sh
(b) Start ResourceManager daemon and NodeManager daemon
Start ResourceManager daemon and NodeManager daemon by executing following command through terminal from
/hadoop3.2.0/sbin/
$ sbin/start-yarn.sh
6. Verify and access the Hadoop services in Browser
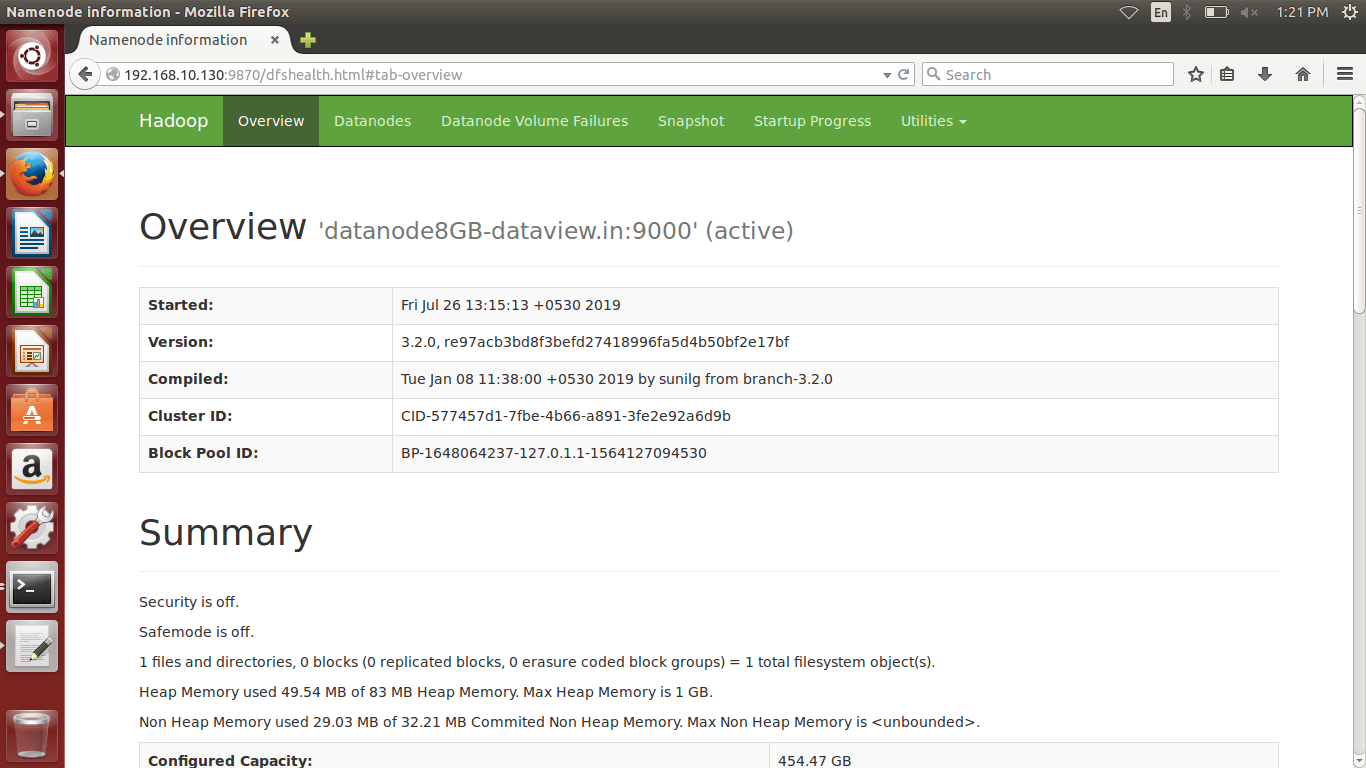
(a) We can browse the web interface for the NameNode; by default it is available at
http://Your IP Address or localhost:9870/
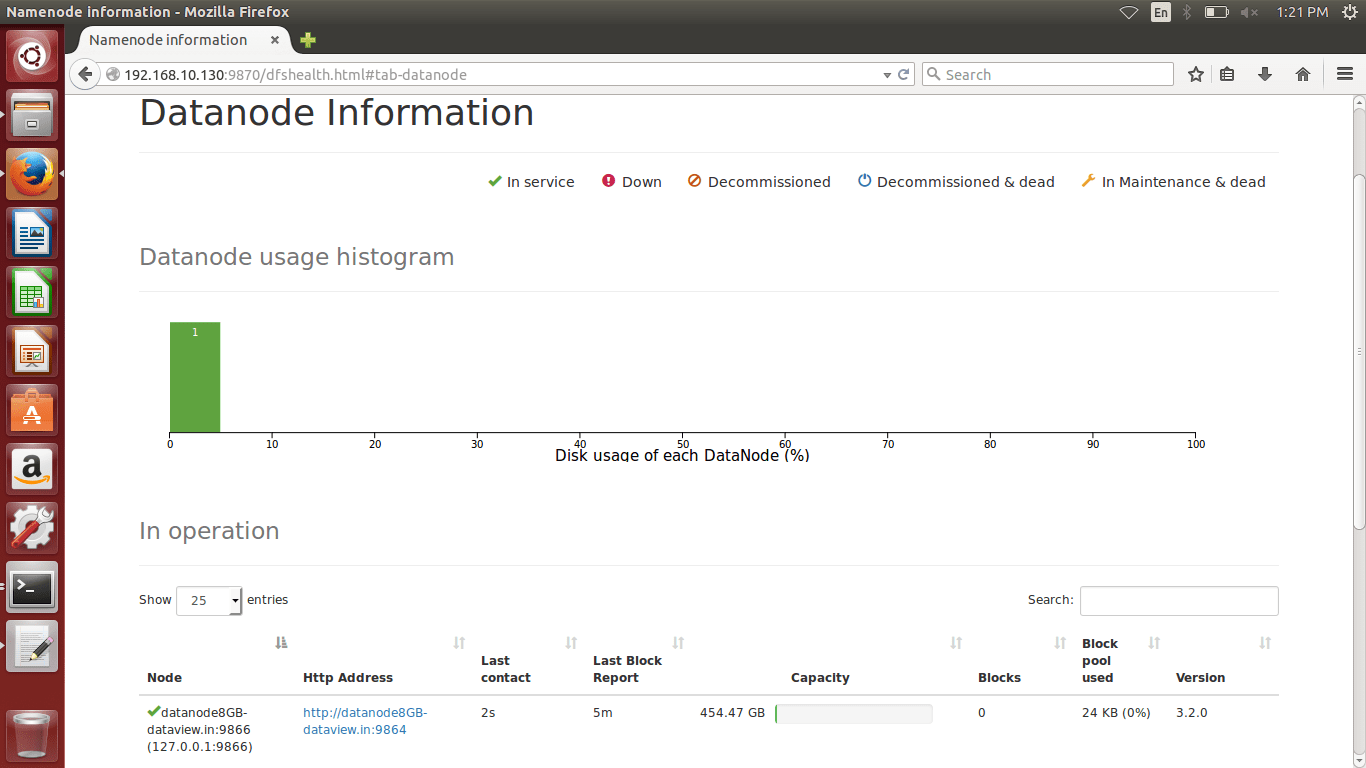
(b) We can browse the web interface for the ResourceManager; by default it is available at
http://Your IP Address or localhost:8088/
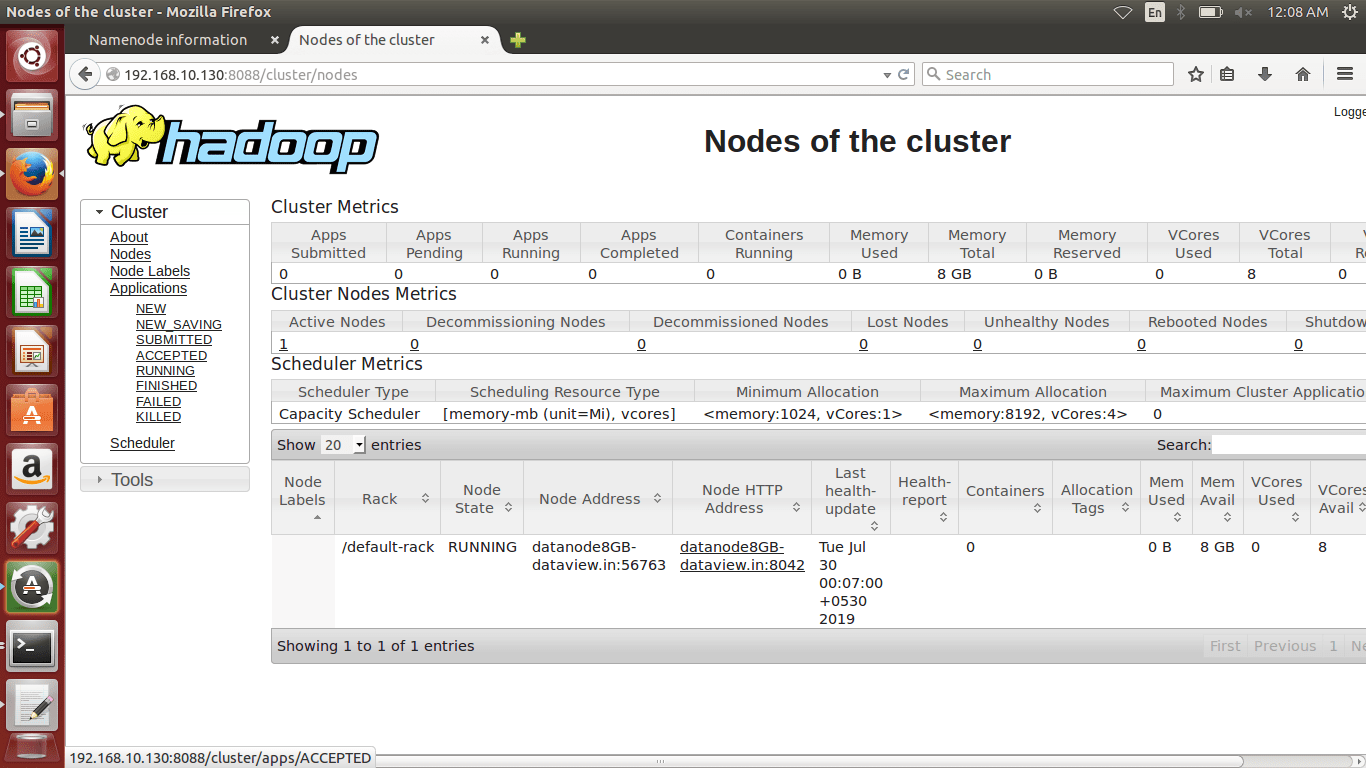
Following commands can be used to stop the cluster
(i) Stop NameNode daemon and DataNode daemon.
$ ./stop-dfs.sh
(ii) Stop ResourceManager daemon and NodeManager daemon
$ ./stop-yarn.sh

Written by
Gautam Goswami ![]()
Can be reached for real-time POC development and hands-on technical training at [email protected]. Besides, to design, develop just as help in any Hadoop/Big Data handling related task. Gautam is a advisor and furthermore an Educator as well. Before that, he filled in as Sr. Technical Architect in different technologies and business space across numerous nations.
He is energetic about sharing information through blogs, preparing workshops on different Big Data related innovations, systems and related technologies.
{kind=link}
Nice. We can try out now with the latest version. Thanks for posting
Great article.