Apache Hadoop-3.2.0 installation on the multi-node cluster with an alternative backup recovery
Hadoop-3.2.0 multi-node cluster
The objective of this article is to explain how we can deploy the latest version of Apache Hadoop (Stable release: 3.2.0 / January 16, 2019) on the multi-node cluster to store unstructured data in a distributed manner. Ideally, this is an expansion procedure from single-node to a multi-node cluster. This multi-node cluster won’t be considered as HA (High Availability) cluster as we have not installed/configured Standby NameNode. But we can retain the exact state of active NameNode if it fails or crashes after post data ingestion into HDFS. To achieve this, we have to manually copy fsimage and edits into external separate location after every post data ingestion into HDFS. However, the following conditions should meet to bring back the cluster into an active state of how it was running before crushing the NameNode.
- Need to maintain the same directory structure what we mentioned previously in core-site.xml, hdfs-site.xml with same version installation
- All the DataNodes should be healthy and no changes occur during the repairing phase of the NameNode system.
Of course, manual intervention will be required to bring back those files into the exact location (directories) and subsequently restart the NameNode. This approach can be followed when there are limited hardware resources. Typically former approach can be beneficial for the small business units who manage different types of data storage in HDFS based Data Lake and avoid cloud-based Data Lake to save revenue. This is recommended who wish to maintain a 3 or maximum 4 node in the cluster but not more than that and also for learning/RD purpose. Advisable to configure Standby NameNode that available with the Apache Hadoop-3.2.0 binary for larger size clusters. From Apache Hadoop 2.x release onwards, the concept of Standby-Namenode has been introduced to overcome the single point of failure. The Standby-Namenode which runs on separate systems and constantly maintains an in-memory, up-to-date copy of the file system namespace of active NameNode since they sync together using a shared directory. So without manual intervention, StandBy NameNode activates immediately and starts functioning if the active Namenode gets down or crushes. We can upgrade this multi-node cluster into HA (High Availability) by adopting the procedures provided by Apache Hadoop-3.2.0 either by Quorum Journal Manager or conventional Shared Storage
Here is a presupposition that Apache Hadoop-3.2.0 already installed and successfully running on Ubuntu-14.04 LTS using the JAVA environment with OpenJDK 11 in a single node cluster and the same would be used in the multi-node cluster. If not installed/created a single-node cluster, here is the link where I articulated step by step. This is an extension of the single-node cluster to a multi-node cluster with three DataNode. The system where a single-node cluster has installed and configured can be considered as NameNode if system configuration is high (At least 16 GB RAM and 1 TB Hard Disk ). I have integrated the system as the NameNode/Master Node where Apache Hadoop-3.2.0 already installed and running as a single-node cluster. Prior to begin, we need to make sure the following
- The systems to run as DataNode are already installed with Ubuntu-14.04
- Created a normal (not root) user account in each system. Maintain the same user id and password across all the system that already using in single-node cluster.
- Updated /etc/hosts file with new static IP address as well as alias name in each system.
- Disabled IPv6 in each system. ipv6 in Ubuntu 14.04 can be disabled by adding the following entry in /etc/sysctl.conf
net.ipv6.conf.all.disable_ipv6 = 1
net.ipv6.conf.default.disable_ipv6 = 1
net.ipv6.conf.eth0.disable_ipv6 = 1
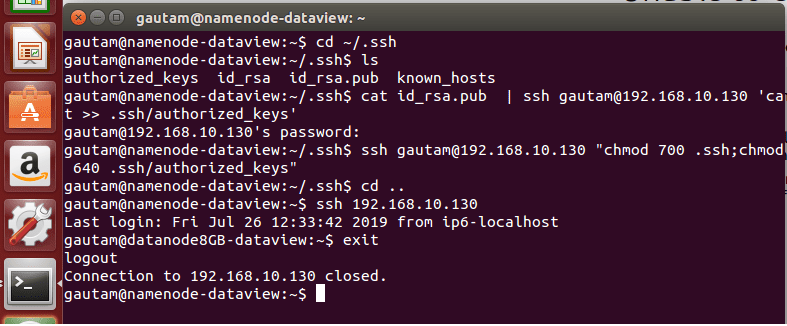
Step 1:- Ensure SSH Passwordless Login from NameNode to all the DataNodes
- Use SSH from NameNode to connect each DataNode in the cluster using created user id as user and create .ssh directory under it.
ssh <<hdadmin>>@<<Static IP address of DataNode>> mkdir -p .ssh - Use SSH from NameNode and upload already generated public key (id_rsa.pub) on each DataNode’s .ssh directory as a file name authorized_keys. [Note:- Public key already generted when we used the NameNode system as Single-node cluster.]
cat .ssh/id_rsa.pub | ssh sheena@<<Static IP address of DataNode>> ‘cat >> .ssh/authorized_keys’
Subsequently set permission
$ chmod 0600 ~/.ssh/authorized_keys - Verify SSH from the NameNode terminal to all the DataNode in the cluster individually to ensure SSH Passwordless Login is working fine.
$ ssh <<DataNode Static IP Address or Alias Name>>
Step 2:- OpenJDK 11 installation on each node
- Install Python Software Properties. can avoid if already installed earlier ($ sudo apt-get install python-software-properties)
- Add repository ($ sudo add-apt-repository ppa:openjdk-r/ppa)
- Update source list ($ sudo apt-get update)
- Install OpenJDK 11 from source list ($ sudo apt install openjdk-11-jdk)
- Update source list again ($ sudo apt-get update )
- After installation of OpenJDK 11, below command to verify the installed version of Java ($ java -version)
![]()
Step-3 NameNode Configuration
We have modified the single node cluster where Apache Hadoop-3.2.0 is running and changed to act as a NameNode in the cluster. Here are the steps
- Update /etc/hosts file with static IP address and alias name which assigned to each DataNode
- Added the alias name/Static IP address of each DataNode in the workers file available inside /hadoop-3.2.0/etc/hadoop
Step-4. Unzip hadoop-3.2.0.tar.gz on each DataNode
- Copy the Hadoop- 3.2.0 binaries to each node from the NameNode
$ cd /home/ hdadmin < logged in user name>/
$ scp hadoop-*.tar.gz DataNode1:/home/hdadmin < logged in user name>
$ scp hadoop-*.tar.gz DataNode2:/home/ hdadmin< logged in user name>
$ scp hadoop-*.tar.gz DataNode3:/home/ hdadmin< logged in user name> - Unzip the binaries/tar ball on
$tar xzf hadoop-3.2.0.tar.gz
$ exit
Repeat steps a and b for other remaining nodes
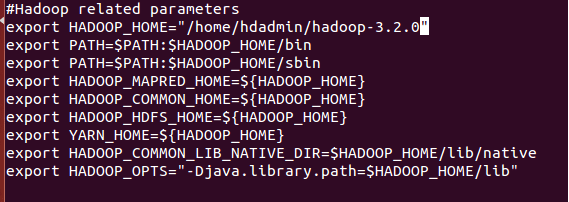
Step- 5 :- Setup Hadoop Environment Variables by editing ~/.bashrc file on each node
$ source ~/.bashrc
Step- 6 :- Update config files on each DataNode
- Replace/rename the default following files on each DataNode and copy those to from the NameNode. Make sure that OpenJDK 11 has installed in same path how it was installed in NameNode. Similarly create directories manually for dfs.nameNode.name.dir as well as dfs.dataNode.data.dir with same path how it was done in NameNode otherwise we will have to modify again in each node for hdfs-site.xml [ core-site.xml, hdfs-site.xml, hadoop-env.sh, mapred-site.xml and yarn-site.xml]$ scp ~/hadoop-3.2.0/etc/hadoop/* $DataNode1:/home/ hdadmin< logged in user name>/hadoop-3.2.0/etc/hadoop/;
- Verify/set JAVA_HOME environment variable in $HADOOP_HOME/etc/hadoop/hadoop-env.sh file .
![]()
Step- 7 :- Add activation1.1.jar
Download or copy activation1.1.jar from older version of Hadoop or JDK and place inside Hadoop common lib directories (hadoop-3.2.0/share/hadoop/common/lib/, hadoop-3.2.0/share/hadoop/yarn/lib/, hadoop-3.2.0/share/hadoop/yarn/activation-1.1.jar). OpenJDK 11 has not included activation1.1.jar.
Step- 8 :- Format NameNode or Master node
We need to format the NameNode before starting the multi- node cluster using following command
$ hdfs namenode -format
Following should appear after successful format of NameNode or Master node
![]()
Step- 9:- Starting the multi-node cluster
- Start NameNode daemon and DataNode daemon by executing following command in /hadoop3.2.0/sbin/ from the terminal of NameNode
$ ./start-dfs.sh - Start NameNode daemon and DataNode daemon by executing following command in /hadoop3.2.0/sbin/ from the terminal of NameNode
$ ./start-yarn.sh
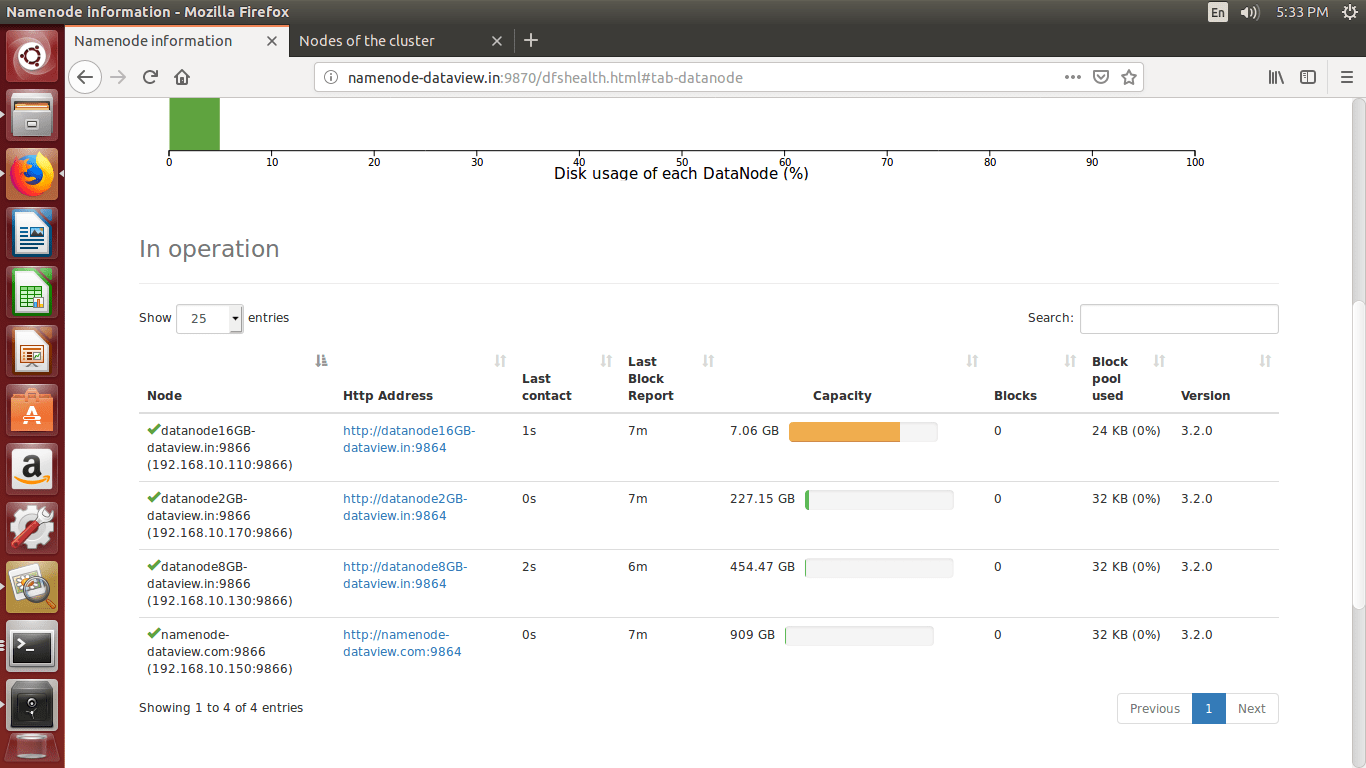
Step-10:- Verify and access the Hadoop services in Browser
- We can browse the web interface for the NameNode; by default it is available at
http://<NameNode IP Address >:9870/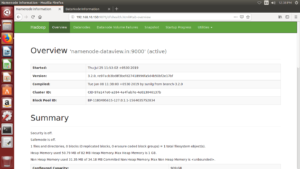
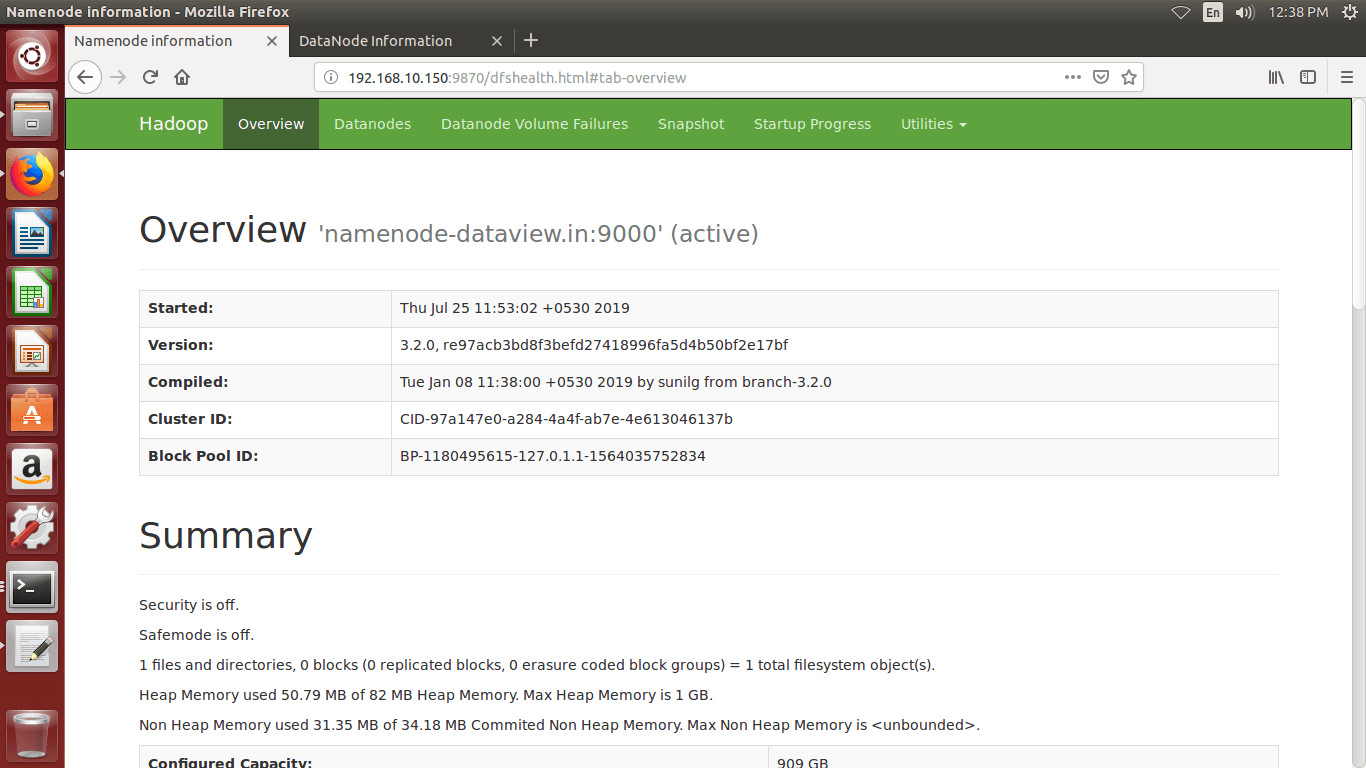
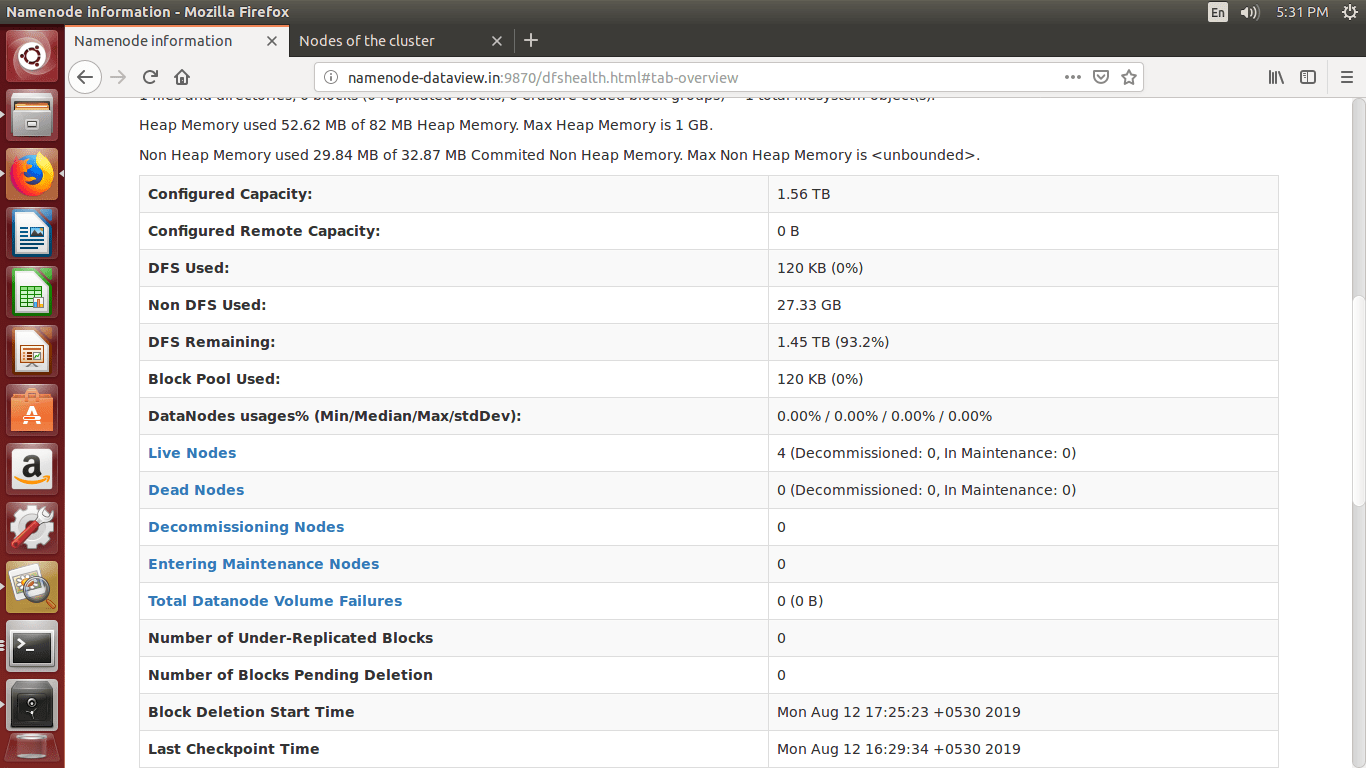
- We can browse the web interface for the ResourceManager; by default it is available at
http://< NameNode IP Address >:8088/
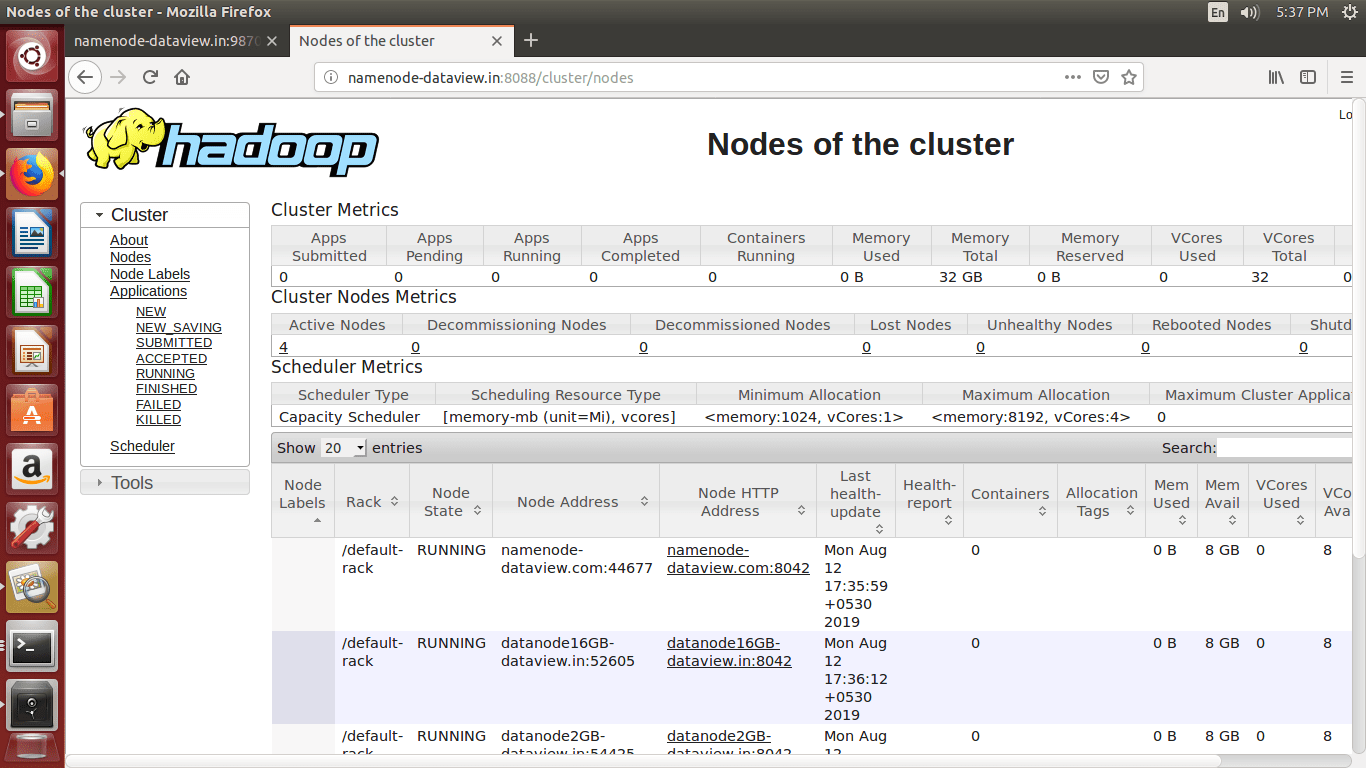
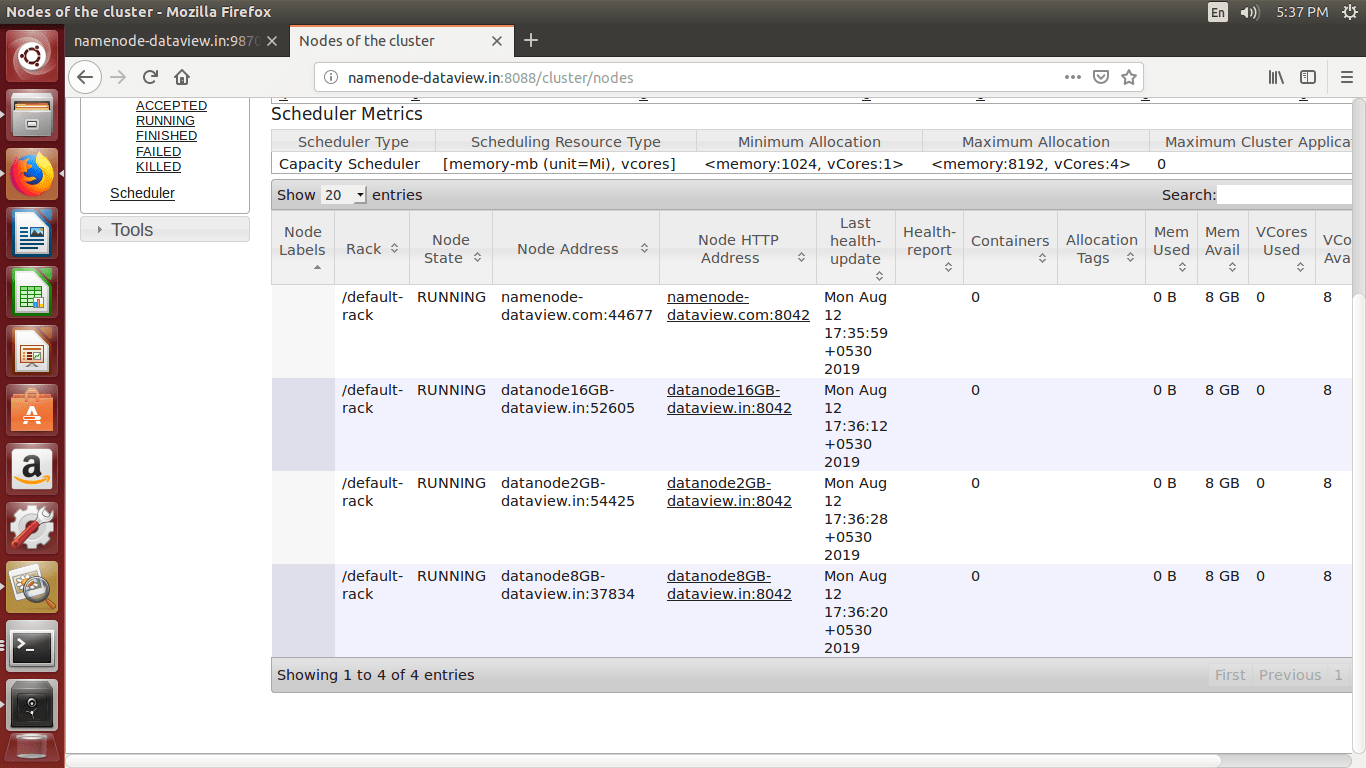
Following commands can be used to stop the cluster
- Stop NameNode daemon and DataNode daemon.
$ ./stop-dfs.sh - Stop ResourceManager daemon and NodeManager daemon
$ ./stop-yarn.sh

Written by
Gautam Goswami ![]()
Can be reached for real-time POC development and hands-on technical training at [email protected]. Besides, to design, develop just as help in any Hadoop/Big Data handling related task. Gautam is a advisor and furthermore an Educator as well. Before that, he filled in as Sr. Technical Architect in different technologies and business space across numerous nations.
He is energetic about sharing information through blogs, preparing workshops on different Big Data related innovations, systems and related technologies.
{kind=link}