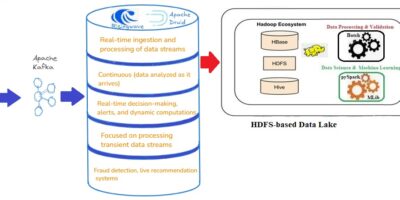
Bridging the Gap: Unlocking the Power of HDFS-Based Data Lakes with Streaming Databases
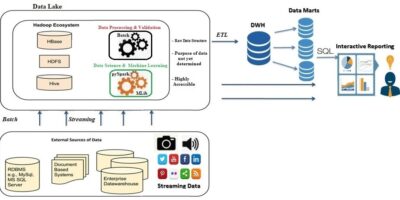
Big data technologies’ quick development has brought attention to the necessity of a smooth transition between real-time data analytics and batch processing systems. Since HDFS (Hadoop Distributed File System) based […]
{kind=link}
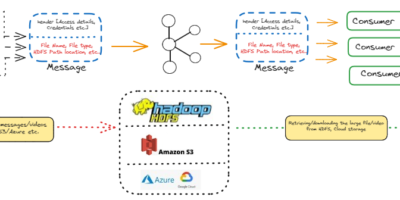
Leveraging Apache Kafka for the Distribution of Large Messages (in gigabyte size range)
In today’s data-driven world, the capability to transport and circulate large amounts of data, especially video files, in real-time is crucial for news media companies. For example, an incident occurred […]
{kind=link}
{kind=link}
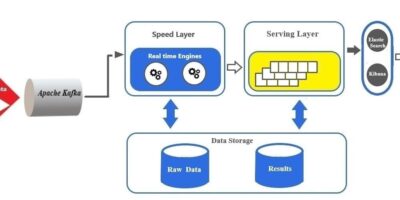
Why Kappa Architecture for processing of streaming data. Have competence to superseding Lambda Architecture?
Data is quickly becoming the new currency of the digital economy, but it is useless if it can’t be processed. The processing of data is essential for subsequent decision-making or […]
{kind=link}
{kind=link}
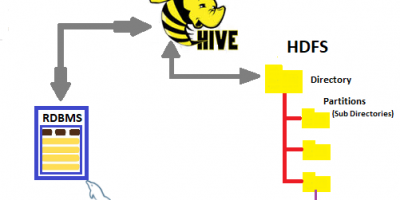
Alternative way of loading or importing data into Hive tables running on top of HDFS based data lake.
Preceding pen down the article, might want to stretch out appreciation to all the wellbeing teams beginning from cleaning/sterile group to Nurses, Doctors and other who are consistently battling to […]
{kind=link}

{kind=link}
{kind=link}
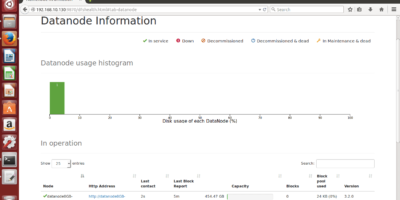
Manual procedure to add a new Datanode into an existing basic data lake without Apache Ambari or Cloudera Manager. Constructed using HDFS (Hadoop Distributed File System) on the multi-node cluster
The aim of this article is to highlight the essential steps when there would be a need for a new DataNode into an exiting multi-node Hadoop cluster. Midsize or startup […]
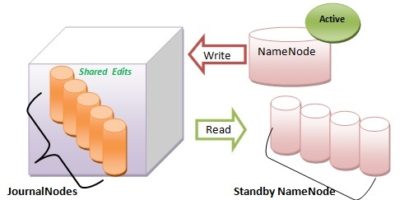
Fault tolerance enhancement on Apache Hadoop 3.0.0-alpha2 by supporting more than 2 NameNodes.
NameNode is the most critical resource in Hadoop core cluster. Once very large files loaded into the Hadoop Distributed File System (HDFS), the files get broken into block-sized chunks as […]
{kind=link}