Alternative way of loading or importing data into Hive tables running on top of HDFS based data lake.
Preceding pen down the article, might want to stretch out appreciation to all the wellbeing teams beginning from cleaning/sterile group to Nurses, Doctors and other who are consistently battling to spare the mankind from continuous Covid-19 pandemic over the globe.
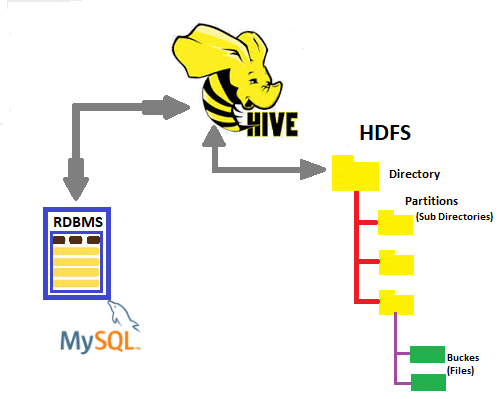
The fundamental target of this article is to feature how we can load or import data into Hive tables without explicitly execute the “load” command. Basically, with this approach Data scientists can query or even visualize directly on various data visualization tool for quick investigation in a scenario when raw data is continuously ingested to HDFS based Data lake from the external sources on consistent schedule. Otherwise, “load” command would be required to execute furthermore for stacking the processed data into Hive’s table. Here we are considering an existing environment with the following components either setup on the Cloud or on premise.
- Multi-node Cluster where HDFS installed and configured. Hive running on top of HDFS with MySQL database as metastore.
- Assuming raw data is getting dumped from multiple sources into HDFS Data lake landing zone by leveraging Kafka, Flume, customized data ingesting tool etc.
- From landing zone, raw data moves to refining zone in order to clean junk and subsequently into processing zone where clean data gets processed. Here we are considering that the processed data stored in text files with CSV format.
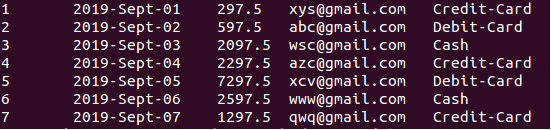
Hive input is directory-based which similar to many Hadoop tools. This means, input for an operation is taken as files in a given directory. Using HDFS command, let’s create a directory in the HDFS using “$ hdfs dfs -mkdir <<name of the folder>> . Same can be done using Hadoop administrative UI depending upon user’s HDFS ACL settings. Now move the data files from the processing zone into newly created HDFS folder. As an example, here we are considering simple order data that ingested into the data lake and eventually transformed to consolidated text files with CSV format after cleaning and filtering. Few lines of rows are as follows
Next step is to create an external table in Hive by using the following command where location is the path of HDFS directory that created on the previous step. here is command we could use to create the external table using Hive CLI. The LOCATION statement in the command tells Hive where to find the input files.

If the command worked, an OK will be printed and upon executing Hive query, Hive engine fetch the data internally from these input text files by leveraging processing engine Map Reducer or other like Spark, Tez etc. Ideally, Spark or Tez can be configured as processing engine in hive-site.xml in order to improve the data processing speed for huge volume of input files.
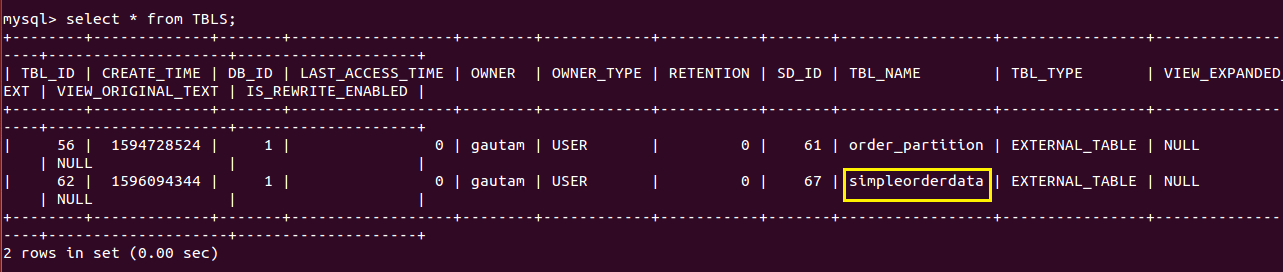
Once the table creation is successful, we can cross check it on “metastore” schema in the MySQL database. To perform that, login to MySQL CLI which might be running on a different node in the cluster and then connect to “metastore” database as well as pulls records from “TBLS” table. This displays the created Hive table information.
The import can be verified through Hive’s CLI by listing the first few rows in the table.
hive> Select * from OrderData;
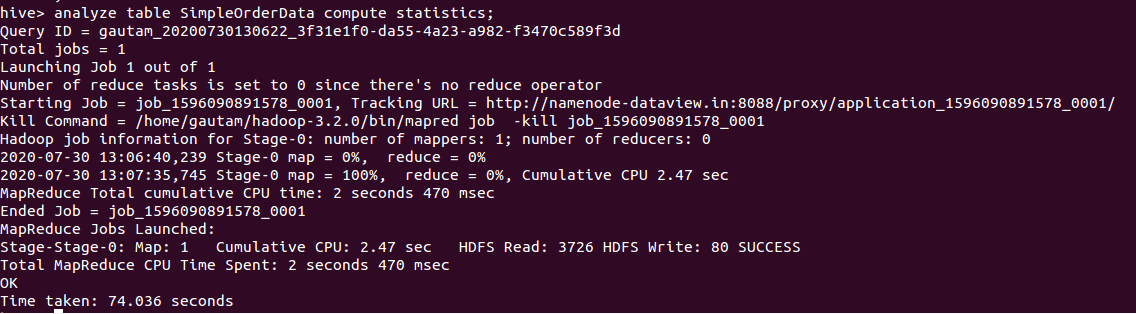
Additionally, “analyze compute statistics” command could be executed in Hive CLI to view the detail information of jobs that runs on that table.
 The primary advantage with this approach is, data can be query, analyze etc within minimum span of time without additionally perform explicit data loading operation. Also helps the Data scientists to check the quality of data before running their machine learning jobs on the data lake or cluster. You could read here how to install and configure Apache Hive on multi-node Hadoop cluster with MySQL as Metastore.
The primary advantage with this approach is, data can be query, analyze etc within minimum span of time without additionally perform explicit data loading operation. Also helps the Data scientists to check the quality of data before running their machine learning jobs on the data lake or cluster. You could read here how to install and configure Apache Hive on multi-node Hadoop cluster with MySQL as Metastore.

Written by
Gautam Goswami ![]()
Can be reached for real-time POC development and hands-on technical training at gautambangalore@gmail.com. Besides, to design, develop just as help in any Hadoop/Big Data handling related task. Gautam is a advisor and furthermore an Educator as well. Before that, he filled in as Sr. Technical Architect in different technologies and business space across numerous nations.
He is energetic about sharing information through blogs, preparing workshops on different Big Data related innovations, systems and related technologies.


{kind=link}