Setup Zookeeper Cluster – A minute chore

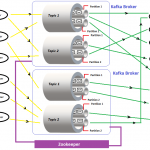
Despite the fact that Apache Zookeeper’s functionalities are not legitimately noticeable to end-client however it remains as the spine for hyped components like Hadoop to oversee automatic failover, Kafka’s broker coordination, Solr, HBase, Apache S4 and some more.
Besides, Zookeeper is being extensively utilized for many free software projects like AdroitLogic UltraESB, Akka, GoldenOrb (massive-scale Graph analysis), Neo4j(Graph Database) etc. On top of it, many esteemed companies like Yahoo, Reckspace, Box, Midokura etc. are using it for their operational purpose.
Before expound the steps to setup multi-node Zookeeper servers/ cluster, should loosens up my thankfulness to all the thriving gatherings beginning from cleaning/sterile social event to Nurses, Doctors and other who are dependably battling to spare the humankind from constant Covid-19 pandemic over the globe.
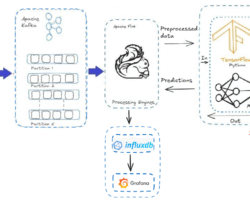
There is no much complicacy to setup a Zookeeper cluster irrespective of the operating system. Zookeeper cluster is also called an ensemble. This article has been segmented into three parts. Additionally, I have added few lines to club the Zookeeper cluster with Kafka for their broker coordination as well as Hadoop to achieve automatic failover on NameNode.
First part:- We would be using a multi-node cluster running on top of Ubuntu 14.04 LTS as OS. There won’t be any bold changes in installation on different OS. Zookeeper runs on JAVA and assuming JAVA is already available on the cluster in each node. Till now Java 9 and 10 are not supported. Can download the latest version of binary from Apache mirror.
Second part:- This section accumulates the install and configuration of Zookeeper in each node on the cluster. The downloaded tarball (apache-zookeeper-3.5.6-bin.tar.gz) has been copied to each node using scp and extracted as
$ tar -xvzf apache-zookeeper-3.5.6-bin.tar.gz
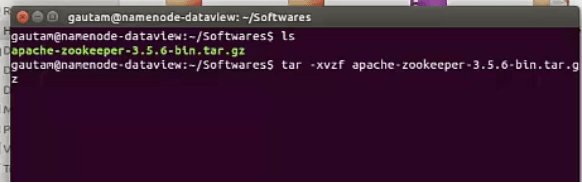
Once extracted successfully, the contents inside the directory apache-zookeeper-3.5.6-bin move to /usr/local/zookeeper location. Make sure “zookeeper” directory already created inside /usr/local with all access permission(root privileged ).
![]()
Now, we have to assign an individual node ID on each of the servers/systems after creating two directories inside “zookeeper” as “data” as well as “logs”.
![]()
subsequently create a ” myid ” file on each system. The myid file consists of a single line containing only the text of that machine’s id. Each myid file will contain a number that correlates to the server number assigned in the configuration file. The id/number must be unique within the cluster and should have a value between 1 and 255. Here we denoted as 1,2,3 and 4 for all four node/systems in the cluster.

The “/usr/local/zookeeper/data” owner is going to be root. Zookeeper stores the process id and snapshot of data in that directory.
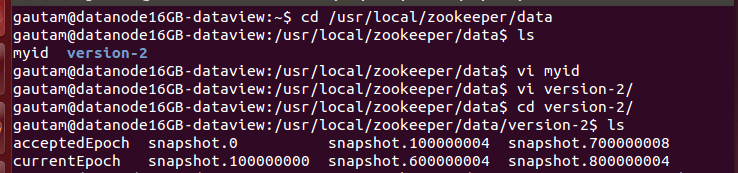
Above screen shot shows the created “myid” file that having unique number as well as snapshots inside “version” directory . The snapshots files will generates automatically once Zookeeper servers starts working.
To update or insert the configuration parameters, the default file zoo_sample.cfg located inside “/usr/local/zookeeper/conf” must be renamed to zoo.cfg.
![]()
and subsequently, update the values for “dataDir” and “clientPort” keys with a new key “dataLogDir “. Since there are 4 nodes in the cluster, zoo.cfg file in each node should be updated with following
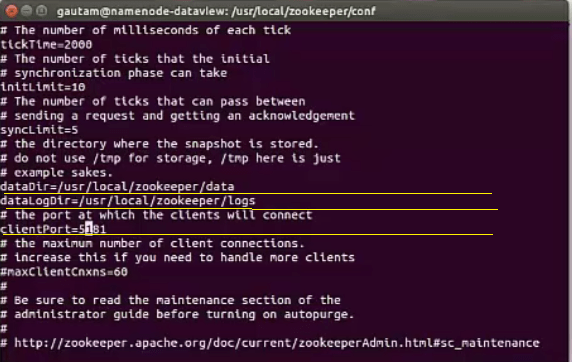
Standalone Zookeeper server is beneficial only for development and testing purposes but not for in production environment. A replicated multi-node cluster is mandatory in production to completely leverage the co-ordination service in a distributed manner. Keeping that in mind, the article has been focused on a multi-node setup. A replicated group of servers in the same application is called a quorum, and in replicated mode, all servers in the quorum have copies of the same configuration file which is zoo.cfg.
Following should be added in each server/node’s zoo.cfg file as well as ” myid ” as stated above.
server.<pid or myid as created above for node 1>=<IP Address of node 1>:2888:3888 [note:- 1 denotes the unique number available inside “myid” file of node/system 1 in the cluster similarly 2,3,4 for other systems]
server.1=192.168.10.130:2888:3888
server.<pid or myid as created for node 2>=<IP Address of node 2>:2888:3888
server.<pid or myid as created for node 3>=<IP Address of node 3>:2888:3888
server.<pid or myid as created for node 4>=<IP Address of node 4>:2888:3888 and so on
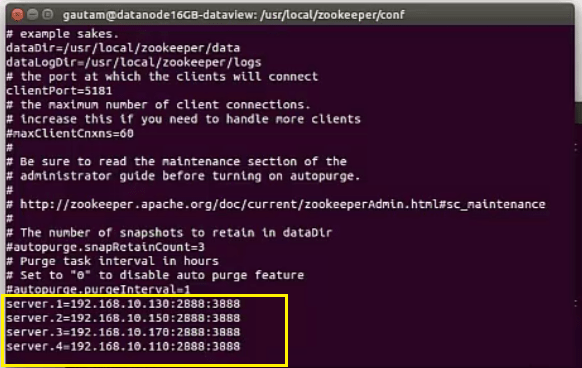
“initLimit” indicates the time within which each of the nodes in the quorum needs to connect to the leader. “syncLimit” specifies the time for sending a request and receiving an acknowledgment. ZooKeeper nodes use a pair of ports :2888 and :3888 for follower nodes to connect to the leader node and for leader election, respectively. Please refer here to know more about configuration parameters.
Third part:- This part is for running and testing the multi-node Zookeeper server installation that we completed on the above parts. We can start each Zookeeper server in all the four nodes/systems by using CLI. Navigate to bin directory (/usr/local/zookeeper/bin) and execute ./zkServer.sh start.
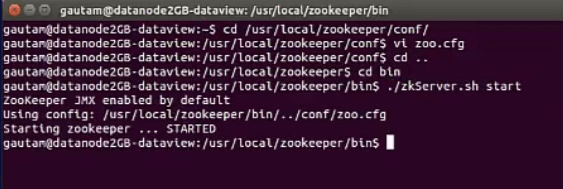
Besides, we can go through the log files in each server to check if any fatel error or exception occurred during each Zookeeper server boot up.

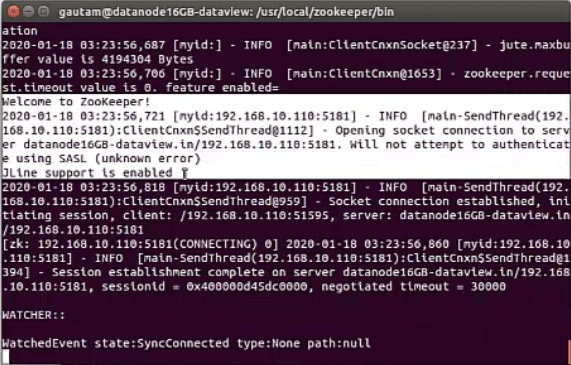
Additionally, using zkCli.sh, we can connect from a different node/system to another node/server.
![]()
After connecting other Zookeeper server using zkCli.sh and appears the following on console then Zookeeper servers are running successfully in the cluster.
This article has not extended with additional information like create sub znode, children of znode, znode metadata etc but would be helpful if someone wants to install and run Kafka cluster. Still, Kafka has decency on Zookeeper for managing their brokers but in near future, Kafka would be disintegrated from Zookeeper. You read here about the upcoming approach.
Eventually, we have reached a section to write few lines on how Zookeeper servers/clusters can be clubbed with Kafka as well as Hadoop multi-node cluster to achieve automatic failover with an assumption that all nodes in the Hadoop cluster already installed and configure Zookeeper as explained above. The ZooKeeper nodes can be arranged on the same hardware as the HDFS NameNode and Standby Node because ZooKeeper itself has light resource requirements. To achieve automatic failover capability in HDFS cluster Apache Zookeeper service is mandatory. Zookeeper maintains a session with the NameNodes in the multi-node Hadoop cluster. On failure of active Namenode, the session maintaining by Zookeeper will expire and inform other NameNodes to initiate the failover process. The ZookeerFailoverController (ZKFC) is a Zookeeper client that monitors and manages the NameNode status. Each of the NameNode runs a ZKFC also. ZKFC is responsible for monitoring the health of the NameNodes periodically. Just going to mention what Zookeeper related configuration parameter will append with Hadoop. The file core-site.xml should be updated for active as well as standby namenode with following.
<property>
<name>ha.zookeeper.quorum</name>
<value> <<IP Address/Alias name of Zookeeper Server 1>>:5181,<< IP Address/Alias name of Zookeeper Server 2>>:5181, <<IP Address/Alias name of Zookeeper Server 3>>:5181 </value>
</property>
Note:- Zookeeper Server 1, Server2, Server 3 are the severs in the Zookeeper Cluster that we installed and configured above.
Skipped other configuration files where Zookeeper’s cluster entry not required but mandatory to be updated/changes for enabling automatic failover in Hadoop.
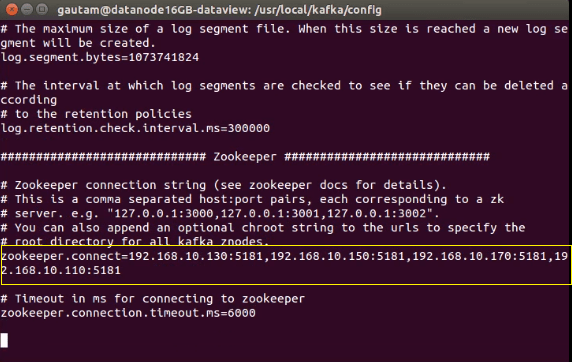
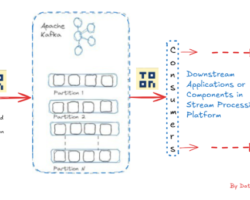
To setup Kafka multi-node cluster even for standalone too, Zookeeper servers entry is mandatory to manage their brokers. In nutshell, Kafka leverages Zookeeper to manage service discovery for Kafka Brokers. Zookeeper handles the responsibility of sending information on changes of the topology to Kafka Cluster and subsequently, each node in the cluster knows when a new broker joined, a Broker died, a topic was removed or a topic was added, etc in the entire Kafka cluster. By entering the Zookeeper’s server info in “server.properties” above can be achieved. The “ server.properties” file resides inside the “conf” directory of each Kafka instance installed on the multi-node cluster.
You can read here about in-depth understanding and roadmap of Zookeeper. Hope you have enjoyed this read.

Written by
Gautam Goswami ![]()
Can be reached for real-time POC development and hands-on technical training at gautambangalore@gmail.com. Besides, to design, develop just as help in any Hadoop/Big Data handling related task. Gautam is a advisor and furthermore an Educator as well. Before that, he filled in as Sr. Technical Architect in different technologies and business space across numerous nations.
He is energetic about sharing information through blogs, preparing workshops on different Big Data related innovations, systems and related technologies.
{kind=link}