Why disintegration of Apache Zookeeper from Kafka is in pipeline

The main objective of this article is to highlight why to cut the bridge between Apache Zookeeper and Kafka which is an upcoming project from the Apache software foundation. Also the proposed architecture/solution aims to make the Kafka completely independent in delivering the entire functionalities that currently offering today with Zookeeper.
Article Structure
This article has been segmented into 4 parts.
- Basic individual functionalities of Zookeeper and Kafka
- Why Kafka can’t work independently without Zookeeper at present
- Pitfalls in Kafka with Zookeeper
- Proposed high level architecture of Kafka without Zookeeper
1. Basic individual functionalities of Zookeeper and Kafka.
Zookeeper is acting as a lever in terms of management and coordination in a distributed environment to manage larger sets of hosts. It’s quite tricky and complicated in a large cluster where more number of a node connected and need to scale horizontally on demand. For example, a Hadoop cluster where new DataNodes plugins once data volume grows, need more replication on data blocks, etc. Apart from Hadoop, it’s being used in other Apache projects like HBase, Solr, CXF DOSGi, etc and others. You can see here the list. Zookeeper plays a key role as a distributed coordination service and adopted for use cases like storing shared configuration, electing the master node, etc. To achieve synchronization, serialization, and coordination, Zookeeper keeps the distributed system functioning together as a single unit for simplicity. Zookeeper takes care of the Race condition, Deadlock, partial failure issues in a distributed application which are very common. Zookeeper’s serialization property eliminates the Race condition in the cluster subsequently Deadlock using synchronization property.
Kafka is an enterprise messing system with the capability of building data pipelines for real-time streaming. Apache Kafka originated at LinkedIn and later became an open-source Apache project in 2011. Besides, Kafka stores the stream of records/data in a fault-tolerant way. Ideally, none of the Big Data related projects gets completed without Kafka because a major part of data ingestion into HDFS taken care of by Kafka through distributed publish-subscribe model. Kafka runs as a cluster on one or more servers and stores stream of data in the topic before consumes eventually by HDFS through Flume or other custom application. By clubbing three major functionality of Kafka namely messaging system, storage system, and stream processing, it is designated as a distributed streaming platform.
2. Why Kafka can’t work independently without Zookeeper at present.
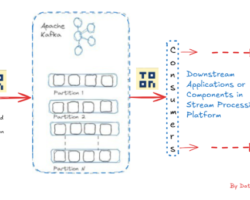
Brokers are the backbone of the Kafka cluster and hold the responsibility of receiving, storing and sending messages from producers to consumers. It’s an instance in the Kafka cluster. In nutshell, groups of brokers create the Kafka cluster by sharing information among them either directly or indirectly. But each broker in the cluster can’t perform this operation without Zookeeper. Besides, producers leverage the zookeeper to find out the information of brokers to where publish the messages.
Similarly consumers too for message consumption from the brokers. Actually, the topic which resides inside the broker accepts the messages from the producers and consumers read from it. Kafka stores the basic metadata in zookeeper like topics, list of Kafka cluster instances, messages consumers, etc.
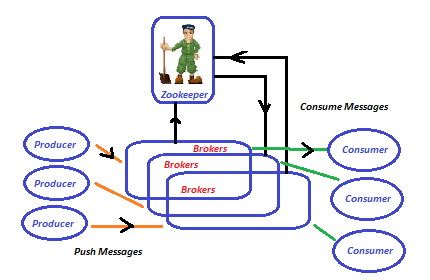
Kafka Zookeeper integration
Zookeeper stands as the leader for Kafka to update the changes of topology in the cluster. Based on the notification provides by Zookeeper, the producers and consumers find the presence of any new broker or failure of the broker in the entire Kafka cluster. Subsequently, producers and consumers decide with which brokers to communicate to start their tasks. So if we install and configure Kafka without Zookeeper, none of the Kafka’s functionality gets active. So eventually we can say the Kafka is a parasite of Zookeeper.
3. Pitfalls in Kafka with Zookeeper
Zookeeper is completely a separate system having its own configuration file syntax, management tools, and deployment patterns. In-depth skill with experience is necessary to manage and deploy two individual distributed systems and eventually up and running Kafka cluster. The person who manages both the system together should have enough troubleshooting information to find out issues in both the systems. There could be a possibility of making mistake on Zookeeper’s configuration files that might lead to breaking down of Kafka cluster. So having expertise in Kafka administration without Zookeeper won’t be able to help to come out from the crisis especially in the production environment where Zookeeper runs on a completely isolated environment (Cloud). Even though to setup and configure a single-node Kafka cluster for learning and R&D, we can’t proceed without Zookeeper.
4. Proposed high level architecture of Kafka without Zookeeper.
The introduction of controller quorum in the Kafka cluster will replace the dependency of Zookeeper. At present, one of the brokers in the Kafka cluster serves as a controller by holding the responsibilities of managing the state of partitions, replicas, administrative tasks like reassigning partitions. In the proposed architecture, the node where the controller is running would take additional responsibility to manage the metadata log.
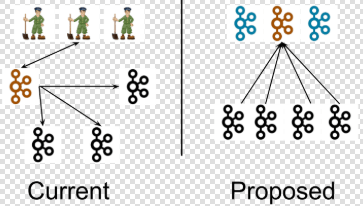
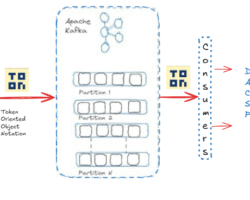
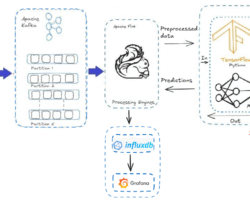
Kafka Zookeeper disintegration .
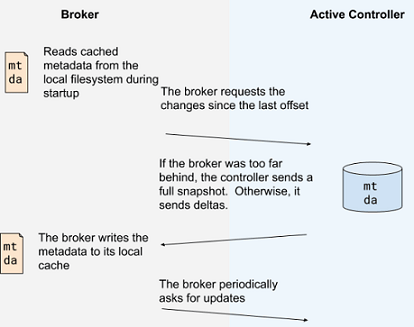
Kafka Zookeeper disintegration
Note:- Above two images are taken from https://cwiki.apache.org/confluence/display/KAFKA/KIP
These logs will encompass the information about every change in the cluster metadata. Currently, Zookeeper storing everything starting from topic, partition, ISRs, configurations. By leveraging the Raft algorithm and without relying on any external system, a leader would be selected amongst themselves by the controller nodes. The leader of the metadata log would be denoted as the active controller.
References:-
https://cwiki.apache.org/confluence/display/KAFKA/KIP
https://cwiki.apache.org/confluence/display/KAFKA/Kafka+Controller+Internals

Written by
Gautam Goswami ![]()
Can be reached for real-time POC development and hands-on technical training at gautambangalore@gmail.com. Besides, to design, develop just as help in any Hadoop/Big Data handling related task. Gautam is a advisor and furthermore an Educator as well. Before that, he filled in as Sr. Technical Architect in different technologies and business space across numerous nations.
He is energetic about sharing information through blogs, preparing workshops on different Big Data related innovations, systems and related technologies.

{kind=link}