Steering number of mapper (MapReduce) in sqoop for parallelism of data ingestion into Hadoop Distributed File System (HDFS)
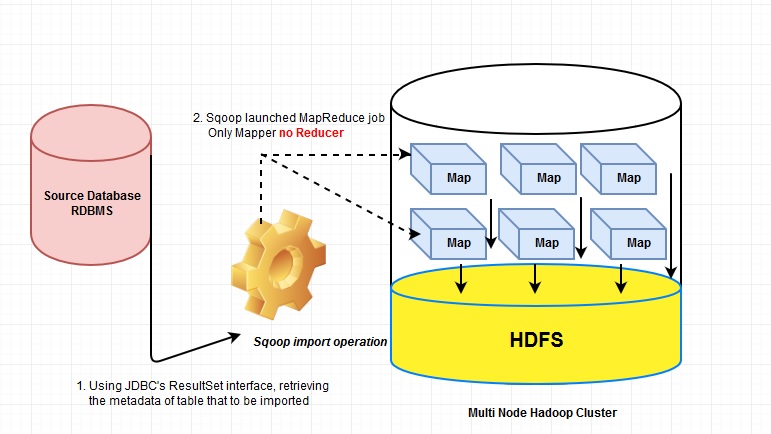
To import data from most the data source like RDBMS, SQOOP internally use mapper. Before delegating the responsibility to the mapper, sqoop performs few initial operations in a sequence once we execute the command on a terminal in any node in the Hadoop cluster. Ideally, in production environment, sqoop installed in the separate node and updated .bashrc file to append sqoop’s binary and configuration which helps to execute sqoop command from anywhere in the multi-node cluster. Most of the RDBMS vendors supply driver class in order to communicate database schema for ETL (Extraction, Transformation and loading). For Oracle(12 c), the JDBC driver class released by Oracle in jar is ojdbc7_g.jar which to be installed/copied inside sqoop’s lib directory ($sqoop_home/lib) since sqoop does not know which JDBC is appropriate. Subsequently, the name of the driver class has to be mentioned in import command.
$sqoop_home/bin$ ./sqoop import –connect :/@url of source database:: –username -P table –target-dir / -m
Before actual import of data into HDFS, sqoop examine and extract all the information of the source database’s table by using JDBC ‘s ResultSet interface that includes list of all the columns and their SQL data types. These SQL types (VARCHAR, INTEGER etc) can then mapped to java data types (String, Integer etc). Here is few code snippet from OracleManager class inside \sqoop-1.4.5-cdh5.3.2\src\java\org\apache\sqoop\manager

JDBC’s ResultSet interface provides a cursor to retrieves records from a query that typically build inside OracleManager class like
select col1, col2, col3, col4, . . . . . . . FROM tableName.
To run an import MapReduce job, sqoop internally invoke the runJob(Job job )method defined in org.apache.sqoop.mapreduce.ImportJobBase.java class. Also used an InputFormat interface which describes the input-specification for a Map-Reduce job and can read the section of the table from the source database by leveraging JDBC.
By default, 4 (four) mapper get initiated that performs the actual data import from RDBMS’s table to HDFS and there is no Reducer because data shuffling is not required among the data node in the cluster. Output of the mapper is the actual data that directly persist into file in the target directory of HDFS . We can specify number of mapper to be operational in the import command as mentioned above. To achieve effective parallelism of data ingestion into multi node HDFS, the number of mapper leverage the split-by column which in terns sqoop build a set of WHERE clauses so that each of the mappers have a logical “slice” of the target table. Suppose a table with id column in source RDBMS has 20,000,00 entries then the id column would have values from 0 to 1,999,999. Sqoop would determine that id as a primary key column for that table while importing to HDFS. Based on the specified number of mapper to run in parallel (-m 6 as example), each map task would have query to execute as
SELECT col1, col2, col3….. from table where id >=0 AND id < 40000, SELECT col1, col2, col3….. from table where id >=40000 AND id < 80000 and so on. Some map tasks might have little or no work to execute if id column were not uniformly distributed. There is an option to specify a particular splitting column when running an import job by passing an argument –split. If we specify one mapper (-m 1), no splitting of column and eventually no parallelism of data ingestion would take place with more time consumption for higher data volume table. To maintain the data consistency in source database as well as in HDFS, we should disable all the process those perform update/modify the existing rows of the table while sqoop importing data.
{kind=link}