Transfer structured data from Oracle to Hadoop storage system
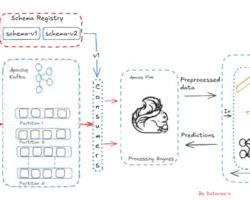
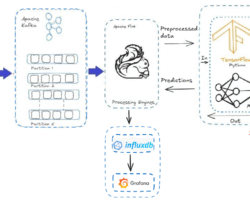
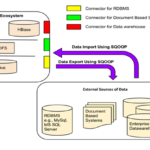
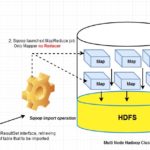
Using Apache Sqoop, we can transfer structured data from Relational Database Management System to Hadoop distributed file system (HDFS). Because of distributed storage mechanism in Hadoop Distributed File System (HDFS), we can store any format of data in huge volume in terms of capacity. In RDBMS, data persists in the row and column format (Known as Structured Data). In order to process the huge volume of enterprise data, we can leverage HDFS as a basic data lake.
In the above video, we have explained how sqoop can be used to transfer data (E-Commerce application’s order related data) from Oracle 11g to HDFS. Here single node cluster has been used where Hadoop 2.x has been installed.
Data ingestion mechanism would be same if sqoop used in multi node cluster or built in the cloud environment like Microsoft Azure, Amazon web service, Google Cloud platform etc.

Written by
Gautam Goswami ![]()
Can be reached for real-time POC development and hands-on technical training at gautambangalore@gmail.com. Besides, to design, develop just as help in any Hadoop/Big Data handling related task. Gautam is a advisor and furthermore an Educator as well. Before that, he filled in as Sr. Technical Architect in different technologies and business space across numerous nations.
He is energetic about sharing information through blogs, preparing workshops on different Big Data related innovations, systems and related technologies.