Manual procedure to add a new Datanode into an existing basic data lake without Apache Ambari or Cloudera Manager. Constructed using HDFS (Hadoop Distributed File System) on the multi-node cluster
The aim of this article is to highlight the essential steps when there would be a need for a new DataNode into an exiting multi-node Hadoop cluster. Midsize or startup data-driven companies are relying nowadays on multi-node Hadoop cluster to store enormous volume of unstructured data for further processing with ELT (Extraction from the source -> Loading to Storing area -> Transformation and process when desire) principle. With the enormous growth of unstructured data, ETL (Extraction -> Transformation -> Loading) becoming a major challenge with traditional RDBMS/Data warehousing system for persistence. Suddenly there might be an urgency to expand the size of existing storing area where data is already ingested and batch processed. Typically this kind of situation arises when client/customers want to add/ingest new data on top of already persisted data and process it to get more insight to compare to the previous result. Adding a new DataNode to the cluster is the best option to expand storage area compare to adding disk into the already running DataNode. In other words, we can say scaling the cluster horizontally. Multiple steps have been explained below in sequence to achieve this with the following assumptions.
– System holding the Name or Master Node in the cluster has avoided Apache Amabari or Cloudera Manager installation due to limited hardware resources.
– Hadoop CDH 2.5.x is installed and running in the existing cluster on OS Ubuntu 14.04
– The system that is designated as new DataNode has 16 GB RAM with the 1TB hard disk. Also, It has to replicate the same user account with administrator privilege from the running DataNode. ssh is installed and sshd is running to use the Hadoop scripts that manage remote Hadoop daemons.
Step -1. Assign static IP address and disable IPv6 in the new DataNode before connecting to the cluster network.
a. Static IP address with alias name of all the existing DataNodes including Master Node has to be added in /etc/hosts file.
b. New alias name along with static IP address of the new DataNode in /etc/hosts file.
c. Modify /etc/network/interfaces to enable eth0 as well as to add address, netmask, gateway. Address in /etc/network/interfaces representing the static IP address of new DataNode.
auto eth0
iface eth0 inet static
address 192.168.xx.xxx
netmask 255.255.255.0
gateway 192.168.xx.x
d. ipv6 in Ubuntu 14.04 can be disabled by adding the following entry in /etc/sysctl.conf
net.ipv6.conf.all.disable_ipv6 = 1
net.ipv6.conf.default.disable_ipv6 = 1
net.ipv6.conf.eth0.disable_ipv6 = 1
e. By default hostname for Ubuntu 14.04 is “Ubuntu” and available in /etc/hostname file. This default hostname has to be replaced with the alias name of new DataNode as defined in /etc/hosts file.
Step -2 Copy “id_rsa.pub” key from Master/NameNode
Since the public key id_rsa.pub already generated during initial deployment phase and available in the master/Namenode, we just need to copy it from the Master/ Name Node terminal to new DataNode. Before that, make sure .ssh directory is available on new DataNode else should be created from Master Node/Name Node terminal.
ssh NewDataNode@ mkdir -p .ssh
MasterNode@admin ~]$ cat .ssh/id_rsa.pub | ssh NewDataNode@192.168.x.XX ‘cat >> .ssh/authorized_keys’
Due to different SSH versions, we need to set permissions on .ssh directory and authorized_keys file in the new DataNode by following command from Master/Name Node terminal.
ssh NewDataNode@ “chmod 700 .ssh; chmod 640 .ssh/authorized_keys”
Once above steps are completed, verify password less login to the new DataNode from Master/Name Node terminal and it should be successful for bi-directional communication between Name Node and New DataNode
~ ssh NewDataNode
Step 3:- Download/Install, Configure Java environment and other requisite
a. Install Python Software Properties
$sudo apt-get install python-software-properties
b. Add Repository
$sudo add-apt-repository ppa:webupd8team/java
(May be changed if other existing nodes using different version )
c. Update the source list
$sudo apt-get update
d. Install Java
$sudo apt-get install oracle-java8-installer
(May be changed if other existing nodes using different version )
Step 5:- Unpack Hadoop Binaries
Copy the Hadoop binaries to the New DataNode assumed to be already available in any existing DataNode or Master/Name Node and unzip subsequently.
cd /home/hadoop/
scp hadoop-*.tar.gz NewDataNode:/home/hadoop
$tar xzf hadoop-2.5.0-cdh5.3.2.tar.gz
Step 6:- Environment variable configuration for Java and Hadoop’s Configuration files.
a. Grant permission to .bashrc file by logged in user
sudo chmod 777 /etc/bash.bashrc
b. Need to update the following parameters in .bashrc file using vi or Ubuntu’s nano editor
$vi ~/.bashrc
export HADOOP_PREFIX=”/home//hadoop-2.5.0-cdh5.3.2″
export PATH=$PATH:$HADOOP_PREFIX/bin
export PATH=$PATH:$HADOOP_PREFIX/sbin
export HADOOP_MAPRED_HOME=${HADOOP_PREFIX}
export HADOOP_COMMON_HOME=${HADOOP_PREFIX}
export HADOOP_HDFS_HOME=${HADOOP_PREFIX}
export YARN_HOME=${HADOOP_PREFIX}
c. After above steps restart the terminal, so that all the environment variables will come into effect
d. Edit configuration file hadoop-env.sh (located in HADOOP_HOME/etc/hadoop) and
set JAVA_HOME:
export JAVA_HOME= path-to-the-root-of-our-Java-installation
(eg: /usr/lib/jvm/java-8-oracle/)
e. Copy the following files from existing DataNode to New DataNode core-site.xml, hdfs-site.xml, yarn-site.xml and mapred-site.xml.
We need to make sure that same directory has been maintained in the New DataNode to avoid any explicit modification for the path. The property “dfs.DataNode.data.dir” and its value is important in hdfs-site.xml. By which, we can specify the URIs/path of the directory where the new DataNode is going to store blocks.
As said, if the same directory structure is maintained with the same user name then nothing should be required to change. Higher than 8 GB RAM for new DataNode, default values in yarn-site.xml for memory allocation can be retained if there is no other cluster specific requirement. Below 8 GB RAM, we can modify yarn-site.xml as well as mapred-site.xml to run MapReduce job to process ingested data to overcome any memory allocation issues. Ideally, the property name “yarn.nodemanager.resource.memory-mb”, “yarn.scheduler.maximum-allocation-mb”, “yarn.scheduler.minimum-allocation-mb” should be updated with Cloudera specific value and “yarn.nodemanager.vmem-check-enabled” with “false” value in yarn-site.xml. Similarly mapred-site.xml for the property “yarn.app.mapreduce.am.resource.mb”, “mapreduce.map.memory.mb”, and “mapreduce.reduce.memory.mb”.
Step 7:- Verify/Copy VERSION file from existing DataNode
Copy the VERSION file from already running existing DataNode into New DataNode. Ideally, the path of the directory for VERSION file can be found at property ” dfs.datanode.data.dir ” in hdfs-site.xml ../etc/hadoop
Step 8 :- Update slaves file in Name/Master node and other nodes
Add the entry of New DataNode alias name inside the slave file of Name/Master node. Alias name for new DataNode is already configured in /etc/hosts file (step 1.b). The file slaves is used by startup scripts to start required daemons on all nodes.
~/hadoop/etc/hadoop/slaves
DataNode01 # existing DataNode alias name
DateNode02 # existing DataNode alias name
DataNode03 # existing DataNode alias name
NewDataNode alias name
Step 9 :- Start datanode Hadoop Services
From the terminal of New DataNode, use the following command to start datanode Hadoop service.
:~/hadoop-2.5.0-cdh5.3.2/sbin $ hadoop-daemon.sh start datanode
Step 10:- Check Hadoop cluster status
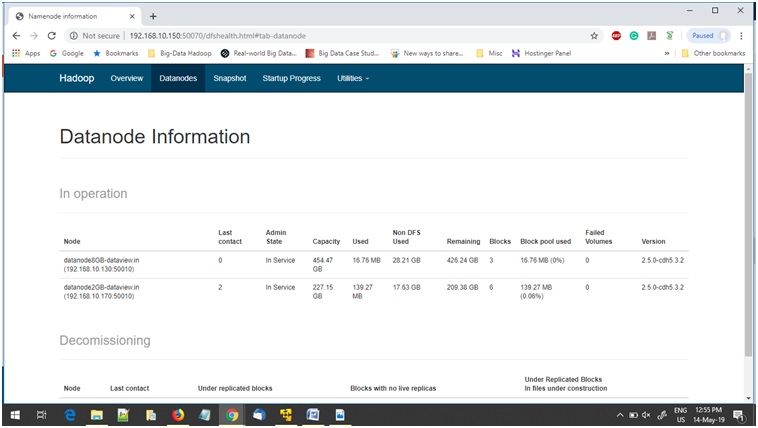
From the terminal of newly added DataNode we can check the status of entire cluster by below command
$ hdfs dfsadmin -report
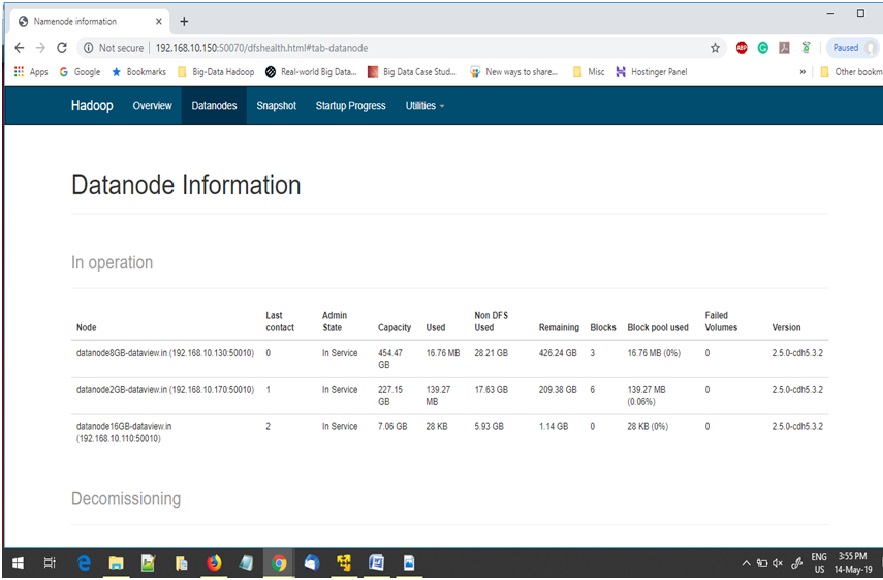
Also by browsing Hadoop monitoring console at http://<Name/Master Node IP>: 50070. The value of “Live Nodes” has been increased by 1 compared to previous value.