Data governance and security mechanism in distributed data storage system

We are very much aware that the traditional data storage mechanism is incapable to hold the massive volume of lightning speed generated data for further utilization even though perform vertical scaling. And going forward we have anticipated only one fuel which is nothing but DATA to accelerate the movement across all the sectors starting from business to natural resources including medical towards rapid growth. But the question is how to persist this massive volume of data to process? The answer is storing the data in a distributed manner in a multi-node cluster where it can be scaled linearly on demand. The former statement is made physically achievable by Hadoop distributed file system (HDFS). Using HDFS we can store data in a distributed manner (multi-node cluster where the number of nodes can be increased in the cluster linearly as data grows). Using hive, HBase we can organize the hdfs data and make it more meaningful as the data become queryable. To accelerate the movement towards growth as mentioned, next hurdle is to govern the data and security implication on this huge volume of persisted data. In a single statement, data governance can be defined as the consolidation of managing data access, accountability and security. By default, HDFS does not provide any strong security mechanism to achieve complete governance but with the additional combination to the following approach, we can proceed towards it.
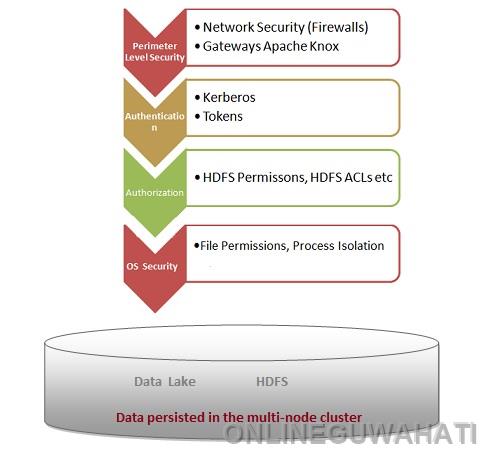
- Integration with LDAP – To secure read/write operation on the persisted data, appropriate authorization with proper authentication is mandatory. Authentication can be achieved in HDFS by integration with LDAP server across all the nodes. LDAP is often used as a central repository for user information and as an authentication service. Organization/Company who has ingested huge data into Hadoop for analysis can define the security policy to avoid data thef, leak, misuse and ensure the right acess to data inside HDFS directories, execute HIVE query etc. User or team need to get authenticated via LDAP server before processing/query data from the cluster. LDAP integration with Hadoop can be done either by using OS level configuration to read LDAP groups or explicitly configuring Hadoop to use LDAP-based group mapping.
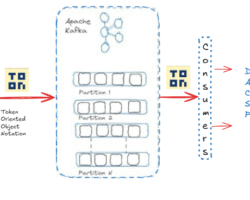
- Introducing Apache Knox gateway – Single access point with multi-node Hadoop clusters can be achieved by Apache Knox for all REST and HTTP interactions. The complex configuration, the client-side library can be wiped out by using Apache Knox. Besides accessing data in the cluster, we can provide security for job execution in the cluster.
- Kerberos for authentication – Kerberos network authentication protocol provides strong authentication for the 2-tier application (client and server). Kerberos server verifies identities for every request when the client wants to access Hadoop cluster. Kerberos Database stores and controls all principles and realms. Kerberos uses secret-key cryptography to enhance strong authentication by providing user-to-server authentication. A Kerberos server, usually called Key Distribution Center (KDC) should be installed on one physical host and it’s database contains the user and service entries like user’s principal, maximum validity, maximum renewal time, password expiration, etc.
- Apache Ranger for centralized and comprehensive data security – By Integrating Apache Ranger with multi-node Hadoop cluster, many requirements mandatory for the governance and security can be fulfilled. It has the capacity to manage all security related tasks via centralized security administration in a central UI or using REST APIs. Besides, Apache Ranger can be utilized effectively to perform fine grained authorization to do a specific action, standardize authorization method across all Hadoop components. Apache Ranger has provided dynamic column masking as well as row level data masking functionality with Ranger specific policies to protect sensitive data from querying out from HIVE table in real time.

Written by
Gautam Goswami ![]()
Can be reached for real-time POC development and hands-on technical training at [email protected]. Besides, to design, develop just as help in any Hadoop/Big Data handling related task. Gautam is a advisor and furthermore an Educator as well. Before that, he filled in as Sr. Technical Architect in different technologies and business space across numerous nations.
He is energetic about sharing information through blogs, preparing workshops on different Big Data related innovations, systems and related technologies.
{kind=link}