Deleting Solr log files/folder from Standby NameNode could be the disaster when Primary NameNode is active in the HDP (Hortonworks Data Platform) Hadoop Cluster

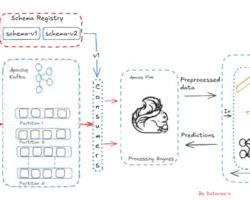
Most of us know that we use Apache Ambari for managing, provisioning and monitor different components of a Hortonworks Hadoop cluster. We also know that Apache Ranger can be used as a centralized security administration solution for Hadoop that enables administrators to create and enforce security policies for HDFS and other Hadoop platform components. When ranger hdfs plugin is enabled,it writes the client
interaction activity to Solr if it is configured. [mailmunch-form id=”787995″]
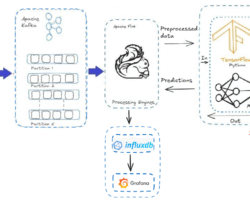
The default location of this solr log files is in HDFS is /var/log/hadoop/hdfs/audit/solr/spool. This can be configured via Ambari as below:
From Ambari, navigate to the right configs panel under HDFS (HDFS–>Config->Advance–>Advanced ranger-hdfs-audit), the value for the parameter “xasecure.audit.destination.solr.batch.filespool.dir” is set as /var/log/hadoop/hdfs/audit/solr/spool as shown below. When this log location is configured, the ranger hdfs plugin starts writing the audit information (in JSON format) to this log file(example: spool_hdfs_20171129-1001.25.log) in both active and standby NameNode.
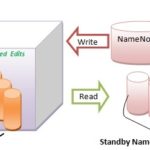
We should be very careful about this folder/file if perform rename or delete operation. In nutshell, this folder, as well as the active file, should not be deleted from secondary NameNode at any cost when the NameNode is active.
If knowingly or unintentionally folder or the current file gets deleted, the result would be shocking. Within 1-2 minutes after deletion, the Secondary NameNode goes down. The same scenario would be repeated after restarting the cluster also. Interestingly no warning/error or exception would appear in any log file to initiate the troubleshooting process why active Secondary NameNode goes down.
Troubleshoot:
To troubleshoot this, we should enable “Audit to HDFS” checkbox(We unchecked or disabled the audit to solar log from HDFS)and define the directory as in shown in figure. Then start the Secondary NameNode from Ambari. This should resolve the issue.

Written by
Gautam Goswami
Can be reached for real-time POC development and hands-on technical training at gautambangalore@gmail.com. Besides, to design, develop just as help in any Hadoop/Big Data handling related task. Gautam is a advisor and furthermore an Educator as well. Before that, he filled in as Sr. Technical Architect in different technologies and business space across numerous nations.
He is energetic about sharing information through blogs, preparing workshops on different Big Data related innovations, systems and related technologies.
{kind=link}