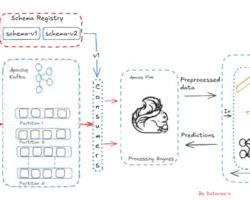
Data Ingestion phase for migrating enterprise data into Hadoop Data Lake
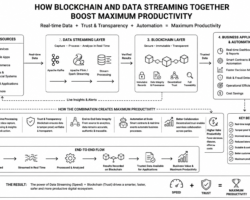
The Big Data solutions helps to achieve valuable information to iron out the accurate strategic business decision. Exponential growth of digitalization, social media, telecommunication etc. are fueling enormous data generation everywhere. Prior to process of huge volume of data, we should have efficient data storage mechanism in a distributed manner to hold any form of data starting from structured to unstructured. Hadoop distributed file systems (HDFS) can be leveraged efficiently as data lake by installing on multi node cluster. Now a day’s, giant cloud service providers are offering built in data lake approach with customization as desired over the cloud. Data ingestion phase plays a critical role in any successful Big Data project. There would be inconsequential outcome if data loss, corrupt partially while ingesting to the Hadoop multi node cluster. Traditional ELT (Extraction from sources then loading into cluster and eventually transformation to process ) can be used like dumping data files through FTP using crone job but have limitations.
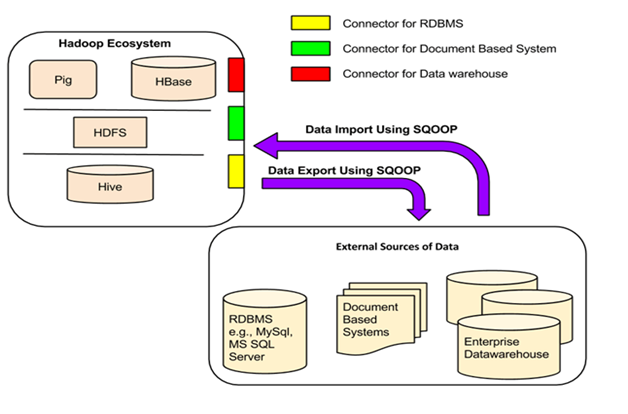
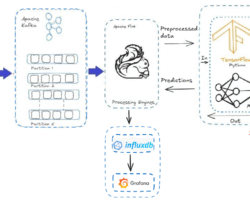
Apache’s Kafka, Flume, Sqoop, Strom are the excellent tools for the data ingestion into the Hadoop cluster. Each of them are designed to collect data from the multiple and different data generation sources. Kafka is a fast, scalable, durable, and fault-tolerant publish-subscribe messaging system and often use in place of traditional message brokers like JMS. Kafka can message sensor data from various equipments. Flume is another distributed, reliable tool for collecting, moving large amount of streaming data into HDFS. As an example, collecting Twitter streaming data and storing on the HDFS for processing and analyzing. There are multiple options available to ingest data from Kafka to HDFS. Using Kafka HDFS connector, we can export data from Kafka topic to HDFS. With the combination of Flume, data can be exported from Kafka topic to HDFS. Flume can be used to read the messages (data) from Kafka topic and write them eventually to HDFS.
Enterprise data has been flooding in at the extraordinary rate in recent years and that force organizations to adopt huge data reservoirs. Traditional cluster of relational databases are almost at the edge of obsolete due to incompatibility of distributed storage, parallel processing, fault tolerant and many more. Since Hadoop data lake addresses all above mentioned constrains, an effective tool is mandatory to transport the enterprise data from the organization’s data repository (Relational Databases)to Hadoop data lake. Apache sqoop has been designed for efficiently transferring bulk data between Hadoop data lake and relational databases such as MySQL or Oracle or a mainframe.
Sqoop is an open source software tool/product from Apache. For databases, Sqoop will read the table row-by-row into HDFS and for mainframe datasets, it will read records from each mainframe dataset into HDFS. The output of this import process is a set of files containing a copy of the imported table or datasets and is performed in parallel. Because of parallel import process, output will be in multiple delimited text files. As an example, with commas or tabs separating each field, or binary Avro or Sequence Files containing serialized record data.
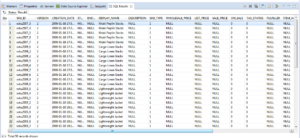
Below figure represents when data is in rest and persisted on RDBMS (Table structure in raw and column)
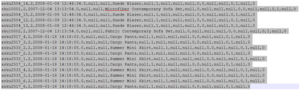
And eventually the above data will convert to file (comma separated )when transported to HDFS using sqoop (below figure).
Sqoop internally automates most of the data transport/transfer process, relying on the database to describe the schema for the data to be imported. Sqoop completely leveraged MapReduce distributed computing to import and export the data, that provides parallel operation as well as fault tolerance. Sqoop provides a pluggable mechanism for optimal connectivity to external systems. The Sqoop extension API provides a convenient framework for building new connectors which can be dropped into Sqoop installations to provide connectivity to various systems. Sqoop itself comes bundled with various connectors that can be used for popular database and data warehousing systems.
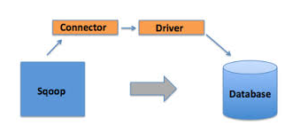
Sqoop delivered or already shipped with connectors for working with popular databases which includes MySQL, Oracle, SQLServer, DB2, Netezza and PostgreSQL. Also a generic JDBC connector for connecting to any database that supports Java’s JDBC protocol. Third party connectors are available for data storage starting from enterprise data warehouse to NoSql stores like Couchbase. Sqoop can be downloaded from Apache software foundation and should be installed on the Hadoop cluster where HDFS has been configured. We need to have the binary of driver class of the specific relational database or other storage systems like Mainframe, Hive, NoSql DB etc from export or import operation in the cluster. So that driver class path can be set while executing the import or export command in Sqoop’s executables.
The order related data already persisted on the ATG database schema (Oracle 11g Enterprise Edition) which belongs to an e-commerce application which is developed on top of Oracle ATG Platform, has been exported to HDFS data lake as a demo.

Written by
Gautam Goswami
Can be reached for real-time POC development and hands-on technical training at gautambangalore@gmail.com. Besides, to design, develop just as help in any Hadoop/Big Data handling related task. Gautam is a advisor and furthermore an Educator as well. Before that, he filled in as Sr. Technical Architect in different technologies and business space across numerous nations.
He is energetic about sharing information through blogs, preparing workshops on different Big Data related innovations, systems and related technologies.
{kind=link}