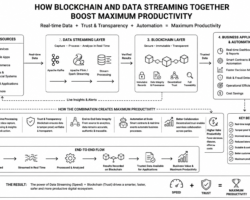
Technology Platform behind Aadhaar card implementation
We are almost familiar with Aadhaar card which had been rolled out as a first initiative in 2003. It’s a 12-digit unique identification number issued by the Indian government to every individual resident of India and that can be used to access a variety of services and benefits.
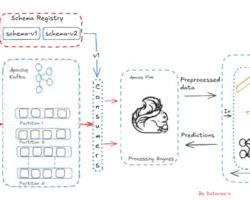
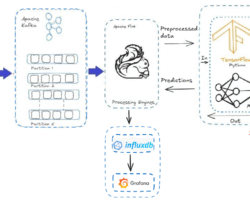
Hadoop is an open-source big data processing framework, that has been customized excessively by the company named MapR to boost performance.The aadhaar card project has been developed using MapR’s customized Hadoop and its eco systems. The design principle of distributed data storage mechanism and parallel data processing made it possible to store 1.2 billion identities (as expected) and will continue to grow as the resident population expands. To achieve such massive scalability, the aadhar card project established network and data center load balancing and a multi-location distributed architecture for horizontal scale.
The security and privacy is the key fundamental of the Aadhaar card project. Resident data and raw biometrics are always kept encrypted that uses 2048-bit PKI encryption and tamper detection using HMAC.
Using parallel data processing paradigm, aadhaar card systems are able to handle hundreds of millions of transactions across billions of records doing hundreds of trillions of biometric matches every day.
As a bird eye view, Hadoop is a combination of two core components viz. Hadoop distributed file system (HDFS) and Map Reduce. HDFS is responsible to store the data in a distributed manner across thousands of physical server and Map Reduce is a computing framework which process the data parallely across the physical servers.

Written by
Gautam Goswami ![]()


{kind=link}