
{kind=link}

{kind=link}
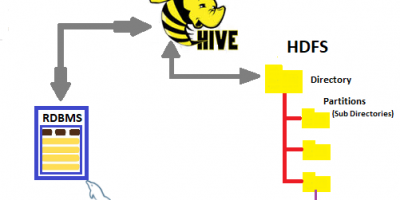
Alternative way of loading or importing data into Hive tables running on top of HDFS based data lake.
Preceding pen down the article, might want to stretch out appreciation to all the wellbeing teams beginning from cleaning/sterile group to Nurses, Doctors and other who are consistently battling to […]
{kind=link}
Install and Configuration of Apache Hive-3.1.2 on multi-node Hadoop-3.2.0 cluster with MySQL for Hive metastore
The apache Hive is a data warehouse system built on top of the Apache Hadoop. Hive can be utilized for easy data summarization, ad-hoc queries, analysis of large datasets stores […]
{kind=link}