Protecting Your Data Pipeline: Avoid Apache Kafka Outages
An Apache Kafka outage occurs when a Kafka cluster or some of its components fail, resulting in interruption or degradation of service. Kafka is designed to handle high-throughput, fault-tolerant data […]
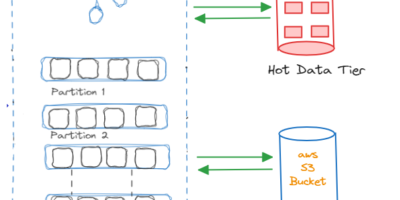
Partitioning Hot and Cold Data Tier in Apache Kafka Cluster for Optimal Performance
At first, data tiering was a tactic used by storage systems to reduce data storage costs. This involved grouping data that was not accessed as often into more affordable, if […]
Overcome LEADER_NOT_AVAILABLE error on Multi-Broker Apache Kafka Cluster
Kafka Connect assumes a significant part in streaming data between Apache Kafka and other data systems. As a tool, it holds the responsibility of a scalable and reliable way to […]
Data Ingestion From RDBMS By Leveraging Confluent’s JDBC Kafka Connector
Kafka Connect assumes a significant part for streaming data between Apache Kafka and other data systems. As a tool, it holds the responsibility of a scalable and reliable way to […]
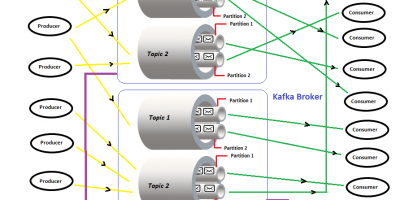
Crafting a Multi-Node Multi-Broker Kafka Cluster- A Weekend Project
Over the most recent couple of years, there has been a huge development in the appropriation of Apache Kafka. Kafka is a scalable pub/sub system and in a nutshell, is […]
This website uses cookies to improve your experience. We'll assume you're ok with this, but you can opt-out if you wish.Got It! ThanksRead More
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these cookies, the cookies that are categorized as necessary are stored on your browser as they are as essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may have an effect on your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.

{kind=link}
{kind=link}
{kind=link}
{kind=link}