{kind=link}
{kind=link}
{kind=link}
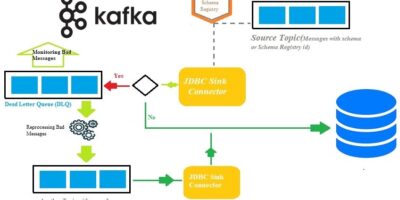
Handling bad messages via DLQ by configuring JDBC Kafka Sink Connector
Any trustworthy data streaming pipeline needs to be able to identify and handle faults. Exceptionally while IoT devices ingest endlessly critical data/events into permanent persistence storage like RDBMS for future […]
{kind=link}
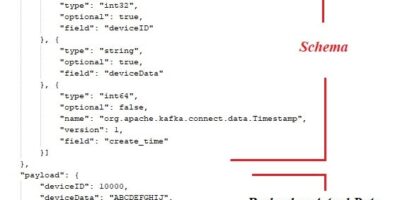
Streaming Data to RDBMS via Kafka JDBC Sink Connector without leveraging Schema Registry
In today’s M2M (Machine to machine) communications landscape, there is a huge requirement for streaming the digital data from heterogeneous IoT devices to the various RDBMS for further analysis via […]
{kind=link}
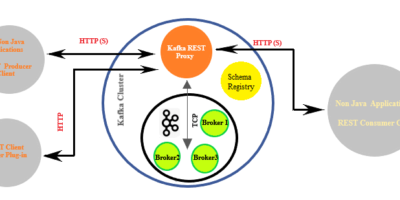
Confluent’s Kafka REST Proxy, The Silk Route for data movement to operational Kafka cluster
Aside from holding the publish-subscribe messaging system functionality, Apache Kafka is gaining outstanding momentum as a distributed event streaming platform. It is being leveraged for high-performance data pipelines, streaming analytics, […]
{kind=link}