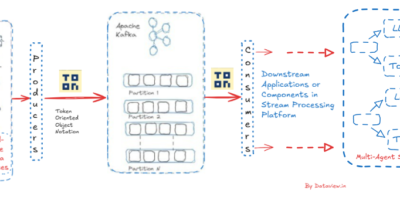
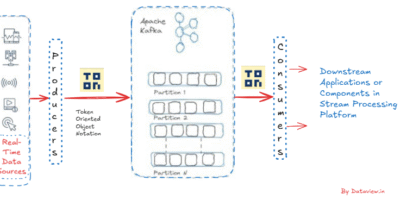
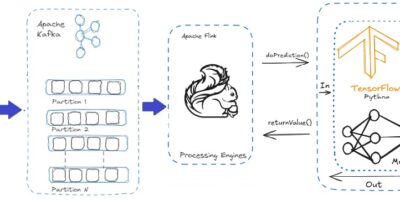
Event-Driven AI Acceleration via TOON on Apache Kafka
AI agents now increasingly require real-time stream data processing as the environment involving the decision making is dynamic, fast-changing, and event-driven. Unlike batch processing which is how traditional data warehouses and […]
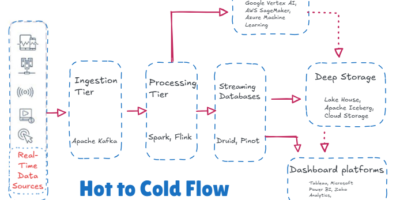

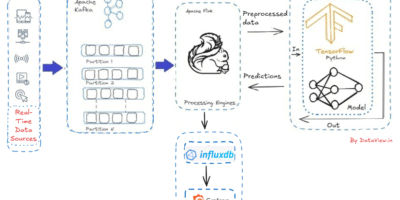
AI on the Fly: Real-Time Data Streaming from Apache Kafka To Live Dashboards
In the current fast-paced digital age, many data sources generate an unending flow of information, a never-ending torrent of facts and figures that, while perplexing when examined separately, provide profound […]

Real-Time at Sea: Harnessing Data Stream Processing to Power Smarter Maritime Logistics
According to the International Chamber of Shipping, the maritime industry has increased fourfold in the last four decades. As the complexity of marine trade increases, ports and shipping companies need […]
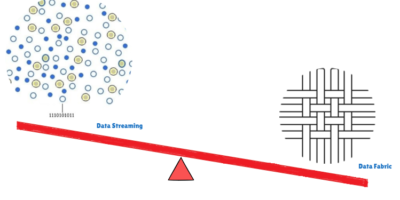
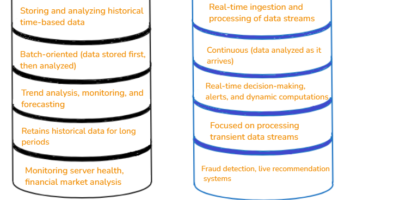
Which Flow Is Best for Your Data Needs: Time Series vs. Streaming Databases
Data is being generated from various sources, including electronic devices, machines, and social media, across all industries. However, unless it is processed and stored effectively, it holds little value. A […]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}