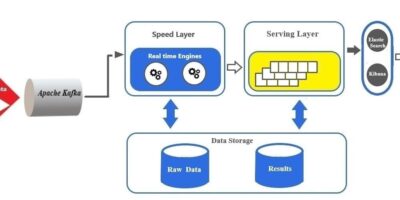
Why Kappa Architecture for processing of streaming data. Have competence to superseding Lambda Architecture?
Data is quickly becoming the new currency of the digital economy, but it is useless if it can’t be processed. The processing of data is essential for subsequent decision-making or […]
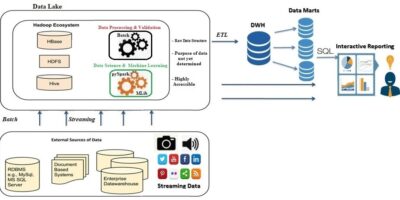
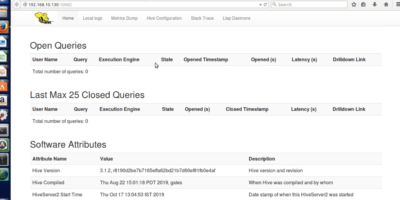
Install and Configuration of Apache Hive-3.1.2 on multi-node Hadoop-3.2.0 cluster with MySQL for Hive metastore
The apache Hive is a data warehouse system built on top of the Apache Hadoop. Hive can be utilized for easy data summarization, ad-hoc queries, analysis of large datasets stores […]
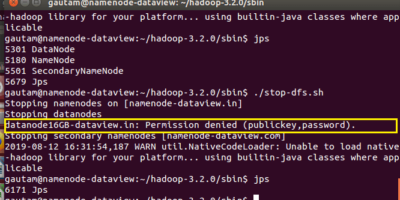
Resolve permission issue among DataNodes with NameNode to establish Secure Shell /SSH without passphrase
Sometimes it has been observed that when we configure and deploy multi-node Hadoop cluster or add new DataNodes, there is a SSH permission issue in communication with Hadoop daemons. In […]
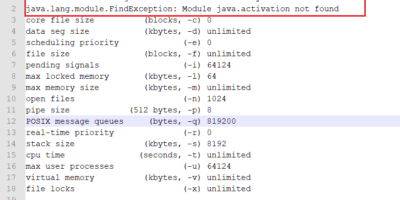
Issue in starting node and resource manager in Apache Hadoop 3.2.0 with OpenJDK 11
Resolved ” Error occurred during initialization of boot layer java.lang.module.FindException: Module java.activation not found” while starting node and resource manager in Apache Hadoop 3.2.0 with OpenJDK 11. It has been […]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}