Hot Data: Where Real-Time Insight Begins
Hot data means the data currently being created, accessed, and queried at real-time or near real-time. The latest and most time-critical data, such as live events, user interactions, sensor measurements, or transaction streams, often require the processing to be right away and latency to be low. Hot (or warm for Gradient Data) has the greatest short-term value, so it is often kept in fast or streaming systems that are designed to process and return data very rapidly to provide instant insights and make lightning decisions.
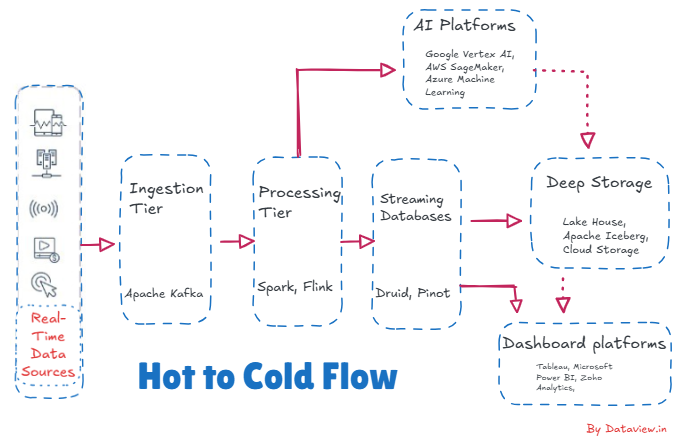
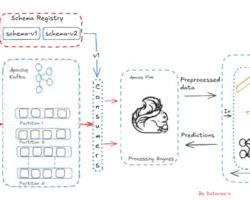
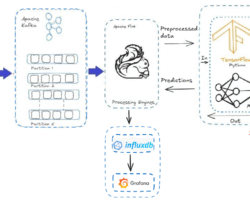
Hot data is so important in stream processing pipelines because it contains the most recent, high-value information you need to make real-time decisions. Hot data processing allows organizations to approximate, in real time, how systems are behaving so they can identify anomalies and react when conditions change by sounding the alarm, personalizing customer experiences, or optimizing operations. Stream processing systems specialize in keeping this data in motion, making sure the data is fresh, accurate, and having immediate business impact.
Typical challenges in hot data processing:
- Low-latency requirements
For hot data, there is no much time for reprocessing in milliseconds or even seconds.
- High data velocity
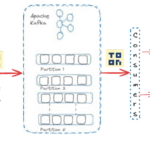
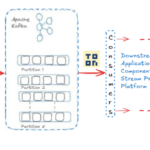
Streams can arrive at very high rate, and it is non-trivial to scale the processing without sacrificing data or facing backpressure.
- State management
It is hard to keep an up-to-date consistent state (windows, aggregates and joins) in real time, especially at scale
- Fault tolerance
Systems should recover rapidly from failures and not lose or duplicate events.
- Data consistency and ordering
Correctness and late/out-of-order/repeated events are difficult to manage.
- Operational complexity
In real-time data pipelines, it is harder for monitoring, debug, and tune due to their continuous nature than batch systems
When data’s business value and accessibility historical past its convenience decrease, warm data cools off. Newly created data in a data lifecycle is“hot,” meaning it needs to be immediate and served up for real-time decisions, alerts, and operational responses. Over time, that same data is used less frequently and no longer needs to be processed at low-latency, so it moves to colder storage and processing layers.
In application, such transition is determined by time, usage, and processing stages. Hot data is first treated in streaming systems (such as Flink or Spark Streaming) and may be enriched or aggregated. After it serves its original purpose, it is compressed, abbreviated, or archived and sent to cost-effective storage – like data lakes, object storage, or warehouses. That cold data is then put to historic analysis, reporting, compliance, or model training, not real-time actions.
Thank you for reading! If you found this article valuable, please consider liking and sharing it.
Written by
Gautam Goswami

{kind=link}