Driving Streaming Intelligence On-Premises: Real-Time ML with Apache Kafka and Flink
Lately, companies, in their efforts to engage in real-time decision-making by exploiting big data, have been inclined to find a suitable architecture for this data as quickly as possible. With many companies, including SaaS users, choosing to deploy their own infrastructures entirely on their own, the combination of Apache Flink and Kafka offers low-latency data pipelines that are built for complete reliability.
Particularly due to the financial and technical constraints it brings, small and the medium size enterprises often have a number of challenges to overcome when using cloud service providers. One major issue is the complexity of cloud pricing models, which can lead to unexpected costs and budget overruns. This article explores how to design, build, and deploy a predictive machine learning (ML) model using Flink and Kafka in an on-premises environment to power real-time analytics.
Why Apache Kafka and Apache Flink?
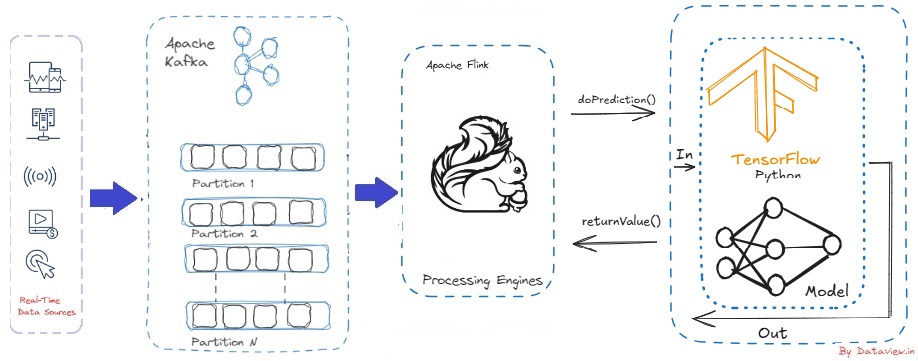
Apache Kafka’s architecture versatility makes it exceptionally suitable for streaming data at a vast ‘internet’ scale, ensuring fault tolerance and data consistency crucial for supporting mission-critical applications. Flink is a high-throughput, unified batch and stream processing engine, renowned for its capability to handle continuous data streams at scale. It seamlessly integrates with Kafka and offers robust support for exactly-once semantics, ensuring each event is processed precisely once, even amidst system failures. Flink emerges as a natural choice for Kafka as a stream processor. Apache Flink enjoys significant success and popularity as a tool for real-time data processing, and accessing sufficient resources. Together, they form a scalable and fault-tolerant foundation for data pipelines that can feed machine-learning models in real time.
Use Case: Predictive Maintenance in Manufacturing
Consider a manufacturing facility where IoT sensors are gathering data from machinery to determine temperature, vibration, and pressure. With the help of this sensor data, we want to minimize downtime by using real-time machine failure prediction and alerting.
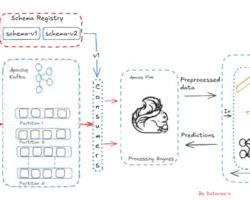
Architecture Overview
- Data Ingestion (Apache Kafka)
- Stream Processing and Feature Engineering (Apache Flink)
- Model Serving (Flink + Embedded ML or External Model Server)
- Real-Time Dashboard or Alert System
Setting Up Kafka and Flink On-Prem
Install Apache Kafka, version 3.8 on dedicated machines. Relying on ZooKeeper on the operational multi-node Kafka cluster introduced complexity and could be a single point of failure. Kafka’s reliance on ZooKeeper for metadata management was eliminated by introducing the Apache Kafka Raft (KRaft) consensus protocol. This eliminates the need for and configuration of two distinct systems—ZooKeeper and Kafka—and significantly simplifies Kafka’s architecture by transferring metadata management into Kafka itself. Configure Kafka topics for each data stream and tune replication plus partition settings for fault tolerance.
To set up an Apache Flink cluster on-premises, first, we will have to prepare or ensure the environment like Java installation on all the nodes, network connectivity, SSH key-based authentication for passwordless, etc. The next step is to configure the cluster where flink-conf.yaml on the master node should be edited and subsequently worker nodes by ensuring that they are configured to connect to the master. The next step is to stream real-time data from Kafka to Flink for processing. With Flink version 1.18.1 onwards, we can directly consume data from Kafka topic without an additional connector.
Designing the Data Pipeline
To design the data pipeline in a nutshell, we can start by defining the topics on the multi-node Kafka cluster and ingest the real-time or simulated IoT sensors data subsequently in JSON or Avro format to Kafka topics. Secondly, we need to use Flink’s DataStream API to consume, parse, and process by fetching the Kafka messages from the topic.
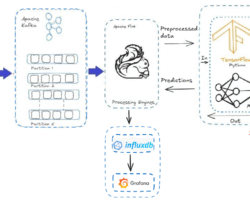
Integrating Machine Learning Models with Apache Flink
Apache Flink is a great stream processing engine for scaling ML models in real-time applications as it supports high-throughput, low-latency data processing. Flink’s distributed architecture allows it to scale horizontally across clusters of machines. ML inference pipelines can be scaled to handle larger throughput simply by increasing resources (CPU, memory, nodes). We can embed trained ML models (from frameworks like TensorFlow, PyTorch, XGBoost, etc.) into Flink jobs. There are typically two main approaches to club models, either by model inference in the Flink Pipelines or model serving with External Systems. In model inference in the Flink Pipelines approach, trained ML models (using libraries like TensorFlow, PyTorch, or Scikit-learn) can be exported and loaded into Flink jobs. These models are often serialized and used for inference within Flink’s operators or functions. With the second approach, ML inference can be offloaded to external model servers/services like NVIDIA Triton, and Flink can interact with these services via asynchronous I/O to keep the pipeline non-blocking and scalable.
Real-Time Metrics Evaluation and System Tracking
For a model monitoring system, Grafana and Prometheus can be a powerful combination. Prometheus is for data collection and storage on the other side Grafana is for visualization and alerting. We need to set up a complete ML model monitoring pipeline using Prometheus and Grafana. Prometheus can collect and store metrics from the ML model integrated with Flink jobs exposing them via an HTTP endpoint. Grafana then connects to Prometheus and visualizes these metrics in real-time dashboards.
Conclusion
As organizations look to capture real-time insights from the data generated within their own environments, deploying on-premises streaming intelligence is not just a technical solution but also a strategic advantage. Apache Kafka’s high-efficiency data ingestion capabilities, combined with Apache Flink’s powerful stream processing and support for real-time machine learning, allow businesses to establish an intelligent pipeline with low latency and high throughput entirely based within enterprise confines. This design not only guarantees data sovereignty and conformity but also allows continuous model inference, adaptive decision-making, and fast response to dynamic events. In this article, I have outlined high-level concepts, but implementing them will involve numerous steps starting from setting up the environment to achieving the desired outcomes. Besides, there are numerous technical problems to solve, including state management in Flink for complex ML models, low-latency predictions at scale, synchronization of model updates, and more.
Thank you for reading! If you found this article valuable, please consider liking and sharing it.
Written by
Gautam Goswami



{kind=link}