The significance of deep storage in Apache Druid
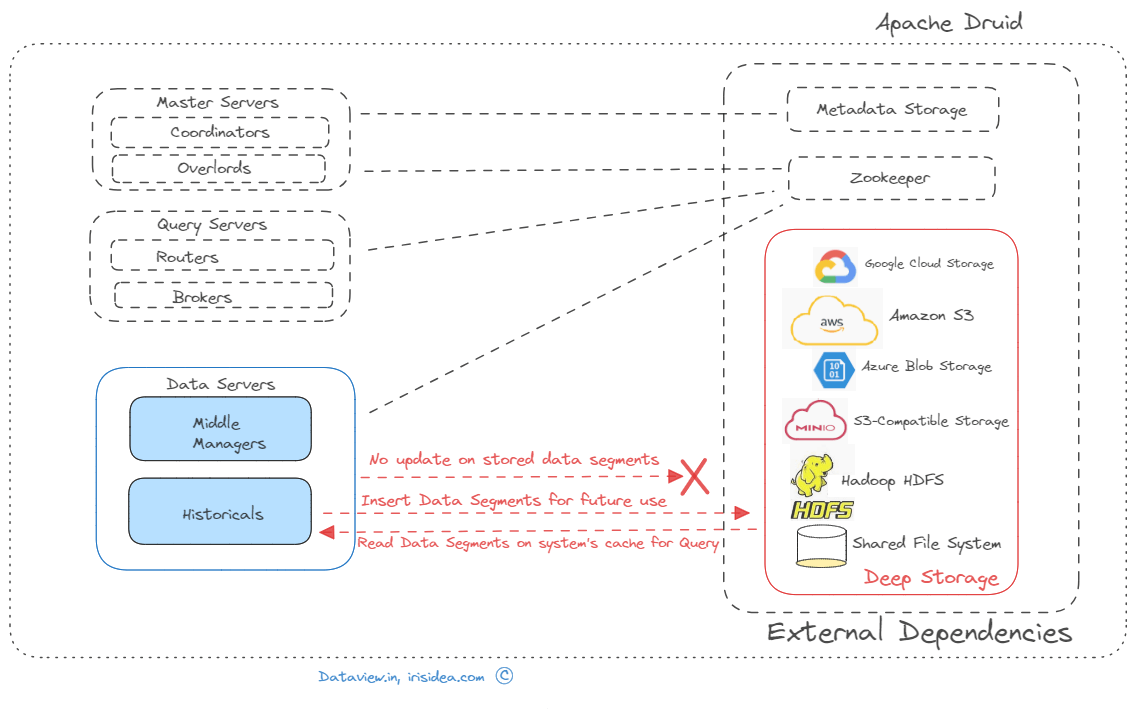
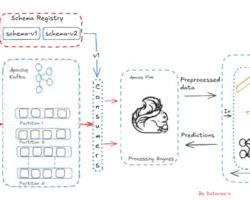
The phrase “deep storage” refers to the long-term storage system used by Apache Druid, where past data segments are preserved for durability and retrieval in the future. Druid stores data in files called segments and deep storage is the place where segments are stored. Even though Druid’s native integration with Apache Kafka (can read here how to integrate Druid with Kafka) and Amazon Kinesis, which allows query-on-arrival at millions of events per second, low latency ingestion, etc., and eventually enables us to fully exploit the potential of streaming data, the deep storage mechanism added another advantage of data durability. Impressively, It’s a type of storage that Apache Druid does not offer.
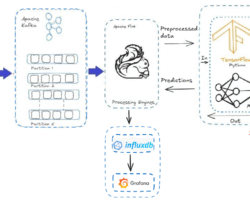
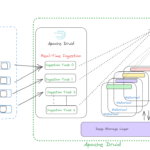
Druid’s Deep storage guarantees long-term data persistence even if data is deleted from the live cluster after compaction. This ensures data longevity and offers data loss protection. In short, Druid stores data in files called segments, and the compaction in Druid can be defined as the process where small segments are merged into larger segments to boost the query performance after data is ingested into Druid. Historical processes of Druid cache data segments on local disk and serve queries from that cache as well as from an in-memory cache. Thus, Druid never needs to access deep storage during a query and helps it offer the best query latencies possible. Additionally, it means that we need to have enough disc space for the data we intend to load across all of our historical servers.
The deep storage system provides a reliable and scalable way to store these compacted segments. It can be configured to use various storage options, such as distributed file systems (e.g., Hadoop Distributed File System – HDFS), cloud object stores (e.g., Amazon S3, Google Cloud Storage), or local file systems. By default, Apache Druid internally configures its deep storage with the local file system after installation on a single node cluster or local system. For multiple Druid server instances, the shared filesystem can be leveraged as deep storage but is not recommended due to difficulties of scalability, etc.
When a segment is compacted and ready to be stored in the deep storage, it is written to the configured storage system. The segment is typically stored as a set of files or objects, organized in a directory structure that corresponds to the Druid segment metadata.
Deep storage in Apache Druid has the following advantages:
- Scalability: By offloading the storage of historical data segments to a separate storage system, Druid can handle large-scale datasets without consuming excessive resources on the live cluster.
- Flexibility: Apache Druid supports multiple deep storage options, giving users the flexibility to choose the storage system that best fits their infrastructure and operational needs.
- Data Durability: Deep storage ensures that data is persisted for the long term, even if it is removed from the live cluster after compaction. This provides data durability and protection against data loss.
- Cost-Effectiveness: Deep storage can leverage cost-efficient storage options such as cloud object stores, allowing organizations to optimize their storage costs based on their requirements and data access patterns.
In conclusion, Apache Druid’s deep storage refers to a long-term storage system where compacted data segments are saved. In Druid’s distributed architecture, it offers durability, scalability, and flexibility for historical data retrieval. Eventually, we will not lose any data no matter how many operational Druid nodes we lose if we configure or use cloud-based deep storage (Amazon S3, Google Cloud Storage, or Azure Blob Storage), S3-compatible storage (like Minio), or HDFS.
Ref:- https://druid.apache.org/docs/latest/dependencies/deep-storage.html
Hope you have enjoyed this read. Please like and share if you feel this composition is valuable. Watch this space for additional articles on handling real-time data streaming and Druid.

Written by
Gautam Goswami ![]()
Can be reached for real-time POC development and hands-on technical training at [email protected]. Besides, to design, and develop just as help in any Hadoop/Big Data handling related task, Apache Kafka, Streaming Data, etc. Gautam is an advisor and furthermore an Educator as well. Before that, he filled in as Sr. Technical Architect in different technologies and business spaces across numerous nations.
He is energetic about sharing information through blogs and preparing workshops on different Big Data related innovations, systems, and related technologies.

{kind=link}
[…] cluster after compaction. This ensures data longevity and offers data loss protection. Please click here to read […]