Partitioning Hot and Cold Data Tier in Apache Kafka Cluster for Optimal Performance
At first, data tiering was a tactic used by storage systems to reduce data storage costs. This involved grouping data that was not accessed as often into more affordable, if less effective, storage array choices. Data that has been idle for a year or more, for example, may be moved from an expensive Flash tier to a more affordable SATA disk tier. Even though they are quite costly, SSDs and flash can be categorized as high-performance storage classes. Smaller datasets that are actively used and require the maximum performance are usually stored in Flash.
Cloud data tiering has gained popularity as customers seek alternative options for tiering or archiving data to a public cloud. Public clouds presently offer a mix of object and file storage options. Object storage classes such as Amazon S3 and Azure Blob (Azure Storage) deliver significant cost efficiency and all the benefits of object storage without the complexities of setup and management.
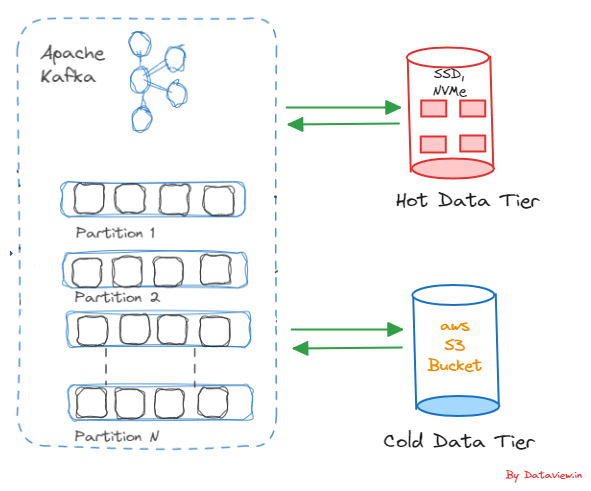
The term “hot” data as well as “cold “ data can be viewed differently from a multi-node Kafka cluster perspective. The data ingested into a Kafka topic and reaching the downstream applications for quick retrieval as the final output after passing through various data pipelines can be termed “hot” data. For example, IoT sensor events from various critical equipment used in oil refineries. Similarly, the ingested data into the Kafka topic that is less frequently accessed by the downstream application can be termed “cold” data. As an example of “cold” data, we can consider inventory updates in e-commerce applications by ingesting product quantities, etc from third-party warehouse systems. The cold data can be moved out from the cluster into a cost-effective storage solution.
After the classification of data that is ingested into a Kafka topic based on the requirements of the downstream application, we can designate data tiers as Hot Tier for hot data and Cold Tier for cold data in the Kafka cluster. High-performance storage options like NVMe (Non-Volatile Memory Express) or SSDs (Solid State Drives) can be leveraged for the Hot data tier, as quick retrieval of data is desired. Similarly, scalable cloud storage services like Amazon S3 can be used for the Cold Tier. Historical and less frequently accessed data that is identified as cold data is ideal for Cold Tier. Of course, the volume of data being ingested into the Kafka topic, as well as the retention period, are also deciding factors for selecting cloud storage.
Basic Execution Procedure at Kafka’s Topic:-
Hot Data Tier:- As mentioned above, SSD or NVMe for the Hot data tier and scalable cloud storage for the Cold data tier and the same can be configured in the Kafka’s server.properties file. Topic configurations have a default setting mentioned in the server.properties file, with an option to override it on a per-topic basis. If no specific value is provided for a topic, the parameters mentioned in the server.properties file will be used. However, using –config option, we can override the configuration of a created topic in the server.properties file.
In this scenario, we want the created topic should store the Hot Tier data in a directory where the location should be on a storage device that offers high-speed access, such as SSDs or NVMe devices.
As a first step, we should disable the automatic topic creation in the server.properties file. By default, Kafka automatically creates topics if they do not exist. However, in a tiered storage scenario, it may be preferable to disable automatic topic creation to maintain greater control over topic configurations. We need to add the following key-value pair in server.properties file.
# Disable Automatic Topic Creation
auto.create.topics.enable=false
In the second step, update the log.dirs property with a location to a storage device that offers high-speed access.
Eventually, point the created topic for Hot data tier using –config option in the server.properties file.
topic.config.my_topic_for_hot_tier= log.dirs=/path/to/SSD or NVMe devices for hot tier
We might need to tweak other key-value pairs in the server.properties file for the Hot Tier depending on our unique use case and requirements such as log.retention.hours, default.replication.factor, and log.segment.bytes.
Cold Data Tier:- As said, scalable cloud storage services like Amazon S3 can be used for the Cold Tier. There are two options to configure the cold tier in Kafka. One is using Confluent’s in-built Amazon S3 Sink connector and the other one is configuring Amazon S3 bucket in Kafka’s server.properties file.
The Amazon S3 Sink connector exports data from Apache Kafka® topics to S3 objects in either Avro, JSON, or Bytes formats. It periodically polls data from Kafka and in turn, uploads it to S3. After consuming records from the designated topics and organizing them into various partitions, the Amazon S3 Sink connector sends batches of records from each partition to a file, which is subsequently uploaded to the S3 bucket. We can install this connector by using the confluent connect plugin install command, or by manually downloading the ZIP file and must install the connector on every machine on the cluster where Connect will run.
Besides the above, we could configure in Kafka’s server.properties file and create a topic for the cold data tier that leverages the S3 bucket using the following steps
– Update the log.dirs property with a location to a S3 storage location. We need to make sure that all necessary AWS credentials and permissions set up for Kafka to write to the specified S3 bucket.
log.dirs=/path/to/S3 bucket
- We can create a topic that will use the Cold Tier (S3) using the built-in script Kafka-topics.sh. Here we need to set the log.dirs configuration for that specific topic to point to the S3 path.
bin/kafka-topics.sh –create –topic our_s3_cold_topic –partitions 5 –replication-factor 3 –config log.dirs=s3://our-s3-bucket/path/to/cold/tier –bootstrap-server <<IP address of broker>>:9092
- According to our requirements and characteristics of S3 storage, we could adjust the Kafka configurations specific to the Cold Tier like modifying the value of retention.hours in server.properties.
As a final note, by partitioning the Hot and Cold Data Tier in Apache Kafka Cluster, we can optimize storage resources based on data characteristics. Scalability and cost-effectiveness of storage become critical as more and more enterprises have started adopting real-time data streaming for their business growth. They can achieve optimal performance and effective cost management of storage by implementing high-performance and cost-effective storage tiers wisely.
Hope you have enjoyed this read. Please like and share if you feel this composition is valuable. Thank you for reading this tutorial.

Written by
Gautam Goswami ![]()
Can be reached for real-time POC development and hands-on technical training at [email protected]. Besides, to design, develop just as help in any Hadoop/Big Data handling related task, Apache Kafka, Streaming Data etc. Gautam is a advisor and furthermore an Educator as well. Before that, he filled in as Sr. Technical Architect in different technologies and business space across numerous nations.
He is energetic about sharing information through blogs, preparing workshops on different Big Data related innovations, systems and related technologies.

{kind=link}