Criticality in Data Stream Processing and a Few Effective Approaches
In the current fast-paced digital age, many data sources generate an unending flow of information, a never-ending torrent of facts and figures that, while perplexing when examined separately, provide profound insights when examined together. Stream processing can be useful in this situation. It fills the void between real-time data collecting and actionable insights. It’s a data processing practice that handles continuous data streams from an array of sources. Opposite to traditional batch data processing technique, here processing works on the data as it is produced in real-time. In simple words, we can say processing data to get actionable insights when it is in motion before stationary on the repository. Data streaming processing is a continuous method of ingestion, processing and eventually analyzing the data as it is generated from various sources. Companies in a wide range of industries are using stream processing to extract insightful information from real-time data like monitoring transactions for fraud detection etc by Financial institutions, Stock market analysis, Healthcare providers tracking patient data, analyzing live traffic data by Transportation companies, etc. Stream processing is also essential for the Internet of Things (IoT). Stream processing enables instantaneous data processing of data provided by sensors and devices, a result of the proliferation of IoT devices.
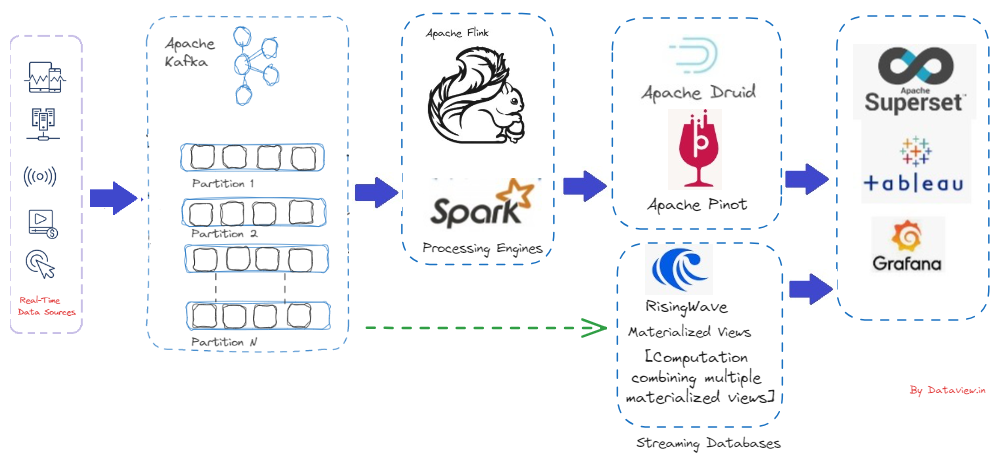
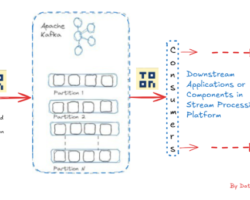
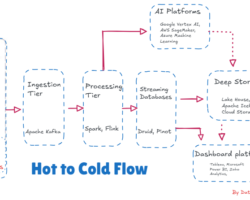
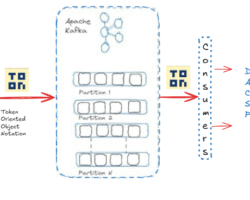
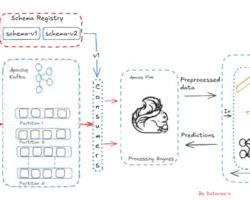
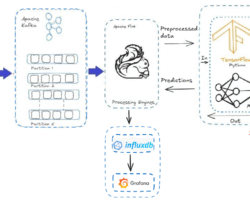
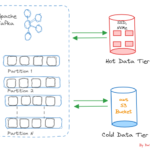
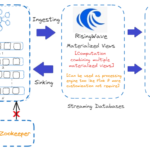
Even with its strength and speed, stream processing has drawbacks of its own. A couple of them as a bird eye view are confirming data consistency, scalability, maintaining fault-tolerance, managing event ordering etc. As said above stream processing is a continuous method of ingestion, processing, and analyzing of data after generation at various source points. Apache Kafka, a popular event streaming platform, can be effectively utilized for the ingestion of stream data from various sources. Once data or events start landing on Kafka’s topic, consumers begin pulling it, and eventually, it reaches downstream applications after passing through various data pipelines if necessary (for operations like data validation, cleanup, transformation, etc.). With the advancement of stream processing engines like Apache Flink, Spark, etc., we can aggregate and process data streams in real-time, as they handle low-latency data ingestion while supporting fault tolerance and data processing at scale. Finally, we can ingest the processed data into streaming databases like Apache Druid, RisingWave, and Apache Pinot for querying and analysis. Additionally, we can integrate visualization tools like Grafana, Superset, etc., for dashboards, graphs, and more. This is the overall high-level data streaming processing life cycle to derive business value and enhance decision-making capabilities from streams of data.
Even though we have event/ data stream ingestion frameworks like Kafka, processing engines like Spark, Flink, etc, and streaming databases like Druid, RisingWave, etc, we encounter a few other challenges if we drill down more like
- Late data arrival
Handling data that arrives out of order or with delays due to network latency is challenging. To tackle this, we need to ensure that late-arriving data is smoothly integrated into the processing pipeline, preserving the integrity of real-time analysis. When dealing with data that arrives late, we must compare the event time in the data to the processing time at that moment and decide whether to process it right away or store it for later.
- Various data serialization formats
Several serialization formats like JSON, AVRO, Protobuf, and Binary, are used for the input data. Deserializing and handling data encoded in various formats is necessary to prevent system failure. A proper exception handling mechanism should be implemented inside the processing engine where parse and return the successful deserialized data else return none.
- Guaranteeing exactly-once processing
Ensuring that each event or piece of data passes through the stream processing engine, guaranteeing ‘Exactly Once Processing’ is complicated to achieve in order to deliver correct results. To support data consistency and prevent the over-processing of information, we will have to be very careful of handling offsets and checkpoints to monitor the status of processed data and ensure its accuracy. Programmatically, we need to ensure and examine whether incoming data has already been processed. If it has, then it should be temporarily recorded to avoid duplication.
- Ensuring at-least-once processing
In conjunction with the above, we need to ensure ‘At-Least Once Processing.’ ‘At-Least Once Processing’ means no data is missed, even though there might be some duplication under critical circumstances. By implementing logic, we will retry using loops and conditional statements until the data is successfully processed.
- Data distribution & partitioning
Efficient data distribution is very important in stream processing and we can leverage partitioning and sharding techniques so that data across different processing units can be achieved load balancing and parallelism. The sharding is a horizontal scaling strategy that allocates additional nodes or computers to share the workload of an application. This helps in scaling the application and ensuring that data is evenly distributed, preventing hotspots and optimizing resource utilization.
- Integrating in-memory processing for low-latency data handling
One important technique for achieving low-latency data handling in stream processing is in-memory processing. It is possible to shorten access times and improve system responsiveness by keeping frequently accessible data in memory. Applications that need low latency and real-time processing will benefit most from this strategy.
- Techniques for reducing I/O and enhancing performance
Reducing the amount of input/output operations is one of the mainstream processing best practices. Because disk IO is usually a bottleneck, this means minimizing the quantity of data that is read and written to the disk. The speed of stream-processing applications can be greatly improved by us by putting strategies like efficient serialization and micro-batching into practice. This procedure guarantees that data flows through the system quickly and lowers processing overhead. Spark uses micro-batching for streaming, providing near real-time processing. Micro-batching divides the continuous stream of events into small chunks (batches) and triggers computations on these batches. Similarly, Apache Flink internally employs a type of micro-batches by sending buffers that contain many events over the network in shuffle phases instead of individual events.
As a final note, the nature of the streamed data itself presents difficulties in streaming data. It flows continuously, in real-time, at a high volume and velocity, as was previously said. Additionally, it’s frequently erratic, inconsistent, and lacking. Data flows in multiple forms and from multiple sources, and our systems should have the capability to manage them all while preventing disruptions from a single point of failure.
Hope you have enjoyed this read. Please like and share if it is valuable.

Written by
Gautam Goswami ![]()
Can be reached for real-time POC development and hands-on technical training at [email protected]. Besides, to design, develop just as help in any Hadoop/Big Data handling related task, Apache Kafka, Streaming Data etc. Gautam is a advisor and furthermore an Educator as well. Before that, he filled in as Sr. Technical Architect in different technologies and business space across numerous nations.
He is energetic about sharing information through blogs, preparing workshops on different Big Data related innovations, systems and related technologies.
{kind=link}