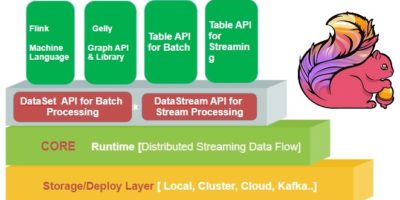
{kind=link}
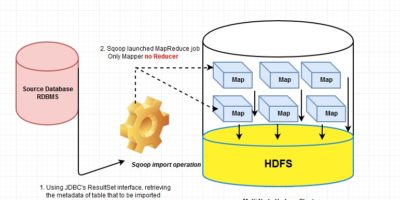
Steering number of mapper (MapReduce) in sqoop for parallelism of data ingestion into Hadoop Distributed File System (HDFS)
To import data from most the data source like RDBMS, SQOOP internally use mapper. Before delegating the responsibility to the mapper, sqoop performs few initial operations in a sequence once […]
{kind=link}
Transfer structured data from Oracle to Hadoop storage system
Using Apache Sqoop, we can transfer structured data from Relational Database Management System to Hadoop distributed file system (HDFS). Because of distributed storage mechanism in Hadoop Distributed File System (HDFS), we […]