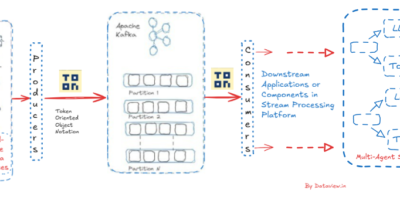
Event-Driven AI Acceleration via TOON on Apache Kafka
AI agents now increasingly require real-time stream data processing as the environment involving the decision making is dynamic, fast-changing, and event-driven. Unlike batch processing which is how traditional data warehouses and […]
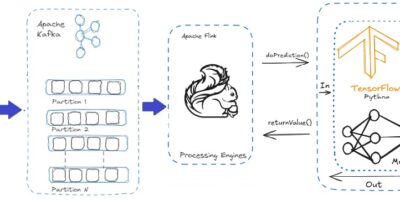
Transferring real-time data processed within Apache Flink to Kafka
Transferring real-time data processed within Apache Flink to Kafka and ultimately to Druid for analysis/decision-making. Businesses can react quickly and effectively to user behavior patterns by using real-time analytics. This […]
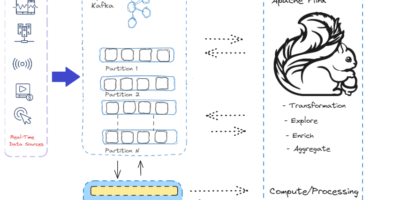
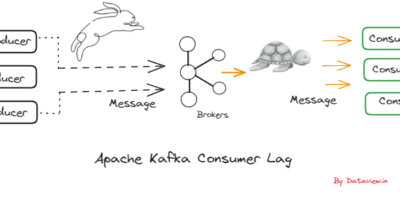
Integrating rate-limiting and backpressure strategies synergistically to handle and alleviate consumer lag in Apache Kafka
Apache Kafka stands as a robust distributed streaming platform. However, like any system, it is imperative to proficiently oversee and control latency for optimal performance. Kafka Consumer Lag refers to […]
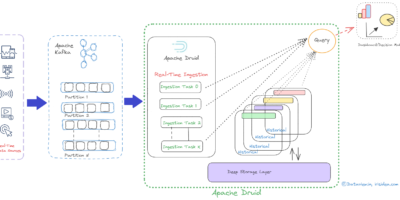
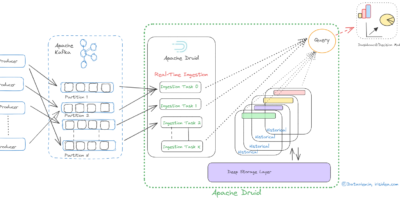
Understanding of Supervisor and it’s specification in Apache Druid for real-time data ingestion from Apache Kafka
Although both Apache Druid and Apache Kafka are potent open-source data processing tools, they have diverse uses. While Druid is a high-performance, column-store, real-time analytical database, Kafka is a distributed […]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}