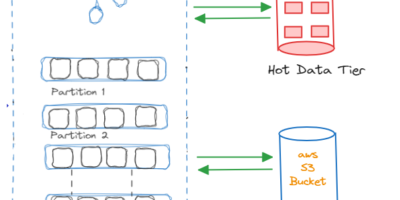
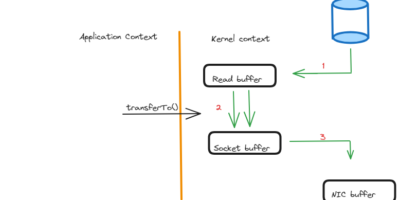
The Zero Copy principle subtly encourages Apache Kafka to be more efficient.
The Apache Kafka, a distributed event streaming technology, can process trillions of events each day and eventually demonstrate its tremendous throughput and low latency. That’s building trust and over 80% […]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}