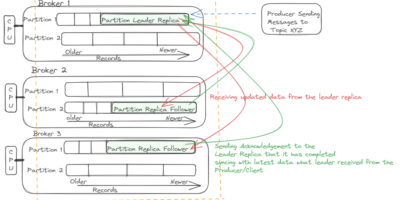
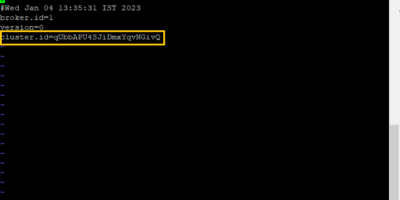
Resolve Apache Kafka starting issue installed on Single/Multi-node cluster
This short article explains how to resolve the error “ERROR Fatal error during KafkaServer startup. Prepare to shutdown (kafka.server.KafkaServer)kafka.common.InconsistentClusterIdException:” when we start the Apache Kafka installed and configured on a […]
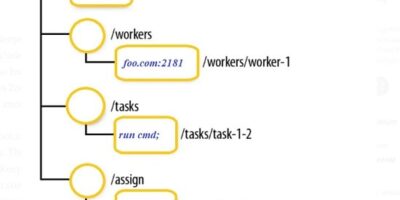
Few intrinsic of Apache Zookeeper and their importance
As a bird’s eye view, Apache Zookeeper has been leveraged to get coordination services for managing distributed applications. Holds responsibility for providing configuration information, naming, synchronization, and group services over […]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}