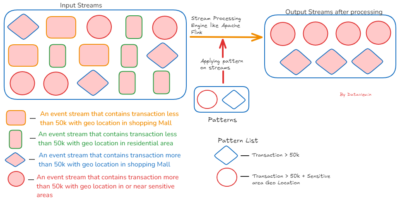
The Significance of Complex Event Processing (CEP) with RisingWave for Delivering Accurate Business Decisions
Complex event processing (CEP) is a highly effective and optimized mechanism that combines several sources of information and instantly determines and evaluates the relationships among events in real-time. It is […]
{kind=link}
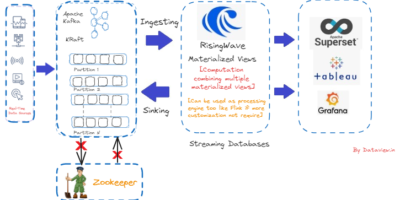
{kind=link}
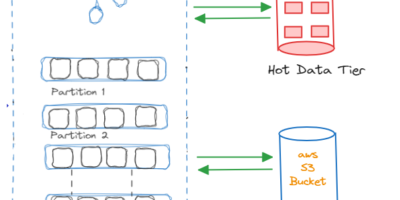
{kind=link}
Exploring Telemetry: Apache Kafka’s Role in Telemetry Data Management with OpenTelemetry as a Fulcrum
With the use of telemetry, data can be remotely measured and transmitted from multiple sources to a single place for control, analysis, and monitoring. The process of gathering data from […]
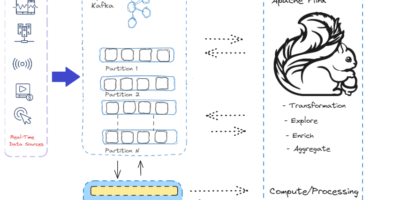
Transferring real-time data processed within Apache Flink to Kafka
Transferring real-time data processed within Apache Flink to Kafka and ultimately to Druid for analysis/decision-making. Businesses can react quickly and effectively to user behavior patterns by using real-time analytics. This […]
{kind=link}
{kind=link}
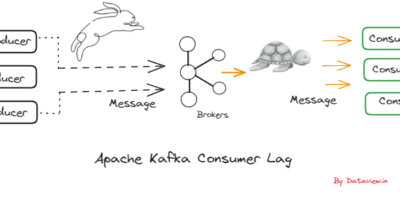
Integrating rate-limiting and backpressure strategies synergistically to handle and alleviate consumer lag in Apache Kafka
Apache Kafka stands as a robust distributed streaming platform. However, like any system, it is imperative to proficiently oversee and control latency for optimal performance. Kafka Consumer Lag refers to […]
{kind=link}
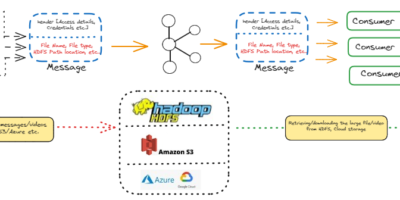
Leveraging Apache Kafka for the Distribution of Large Messages (in gigabyte size range)
In today’s data-driven world, the capability to transport and circulate large amounts of data, especially video files, in real-time is crucial for news media companies. For example, an incident occurred […]
{kind=link}
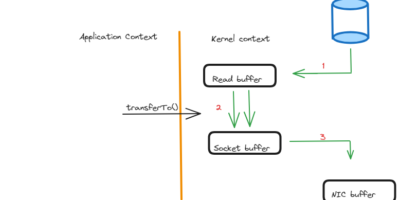
The Zero Copy principle subtly encourages Apache Kafka to be more efficient.
The Apache Kafka, a distributed event streaming technology, can process trillions of events each day and eventually demonstrate its tremendous throughput and low latency. That’s building trust and over 80% […]
{kind=link}