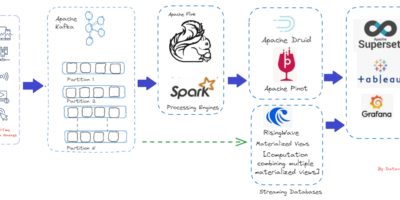
Transferring real-time data processed within Apache Flink to Kafka
Transferring real-time data processed within Apache Flink to Kafka and ultimately to Druid for analysis/decision-making. Businesses can react quickly and effectively to user behavior patterns by using real-time analytics. This […]
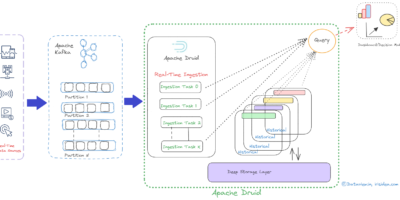
Understanding of Supervisor and it’s specification in Apache Druid for real-time data ingestion from Apache Kafka
Although both Apache Druid and Apache Kafka are potent open-source data processing tools, they have diverse uses. While Druid is a high-performance, column-store, real-time analytical database, Kafka is a distributed […]
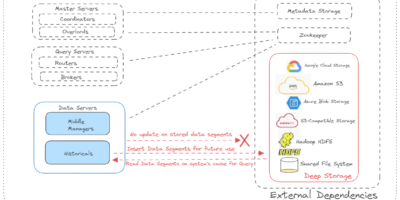
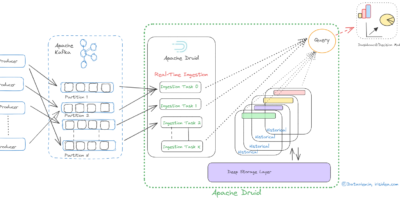
{kind=link}
{kind=link}
{kind=link}
{kind=link}