Apache Kafka’s built-in command line tools – A hidden gem to scan internals.
Several tools/scripts are included in the bin directory of the Apache Kafka binary installation. Even if that directory has a number of scripts, through this article I want to highlight the five scripts/tools that I believe will have the biggest influence on your development work mostly related to real-time data streaming processing.
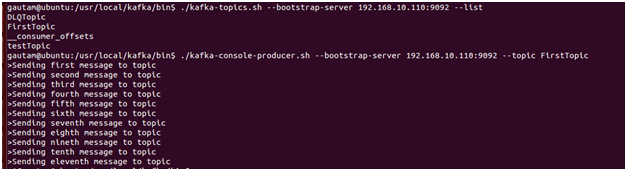
After setting up the development environment followed by installation and configuration of either with single-node or multi-node Kafka cluster, the first built-in script or tool is kafka-topic.sh.
- Kafka-topics.sh
Using kafka-topic.sh, we can create a topic on the cluster to publish and consume some test messages/data. Subsequently, alter the created topic, delete a topic, change/modify the replication factor, number of partitions for that topic, list of topics created on the cluster, etc, and so on.
![]()
2. Kafka-console-producer.sh
We may directly send records to a topic from the command line using this console producer script. Typically, this script is an excellent method to test quickly whether the dev or staging Kafka single/multi-node setup is working or not. Also very helpful to quickly test new consumer applications when we aren’t producing records to the topics yet by integrating messages/records senders apps or IOT devices etc.
kafka-console-producer –topic <<topic name>> /
–broker-list <broker-host:port>
Even though the above method of using the command line producer just sends values rather than any keys, by using the key.separator we could send full key/value pairs too.
kafka-console-producer –topic \
–broker-list <broker-host:port> \
–property parse.key=true \
–property key.separator=”:”
![]()
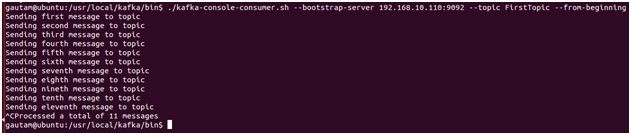
3. Kafka-console-consumer.sh
Now let’s look at record consumption from the command line, which is the opposite side of the coin. We may directly consume records from a Kafka topic using the console consumer’s command-line interface. Quickly starting a consumer may be a very useful tool for experimenting or troubleshooting. Run the below command to rapidly verify that our producer application is delivering messages to the topic. To see all the records from the start, we can add a –from-beginning flag to the command, and we’ll see all records produced to that topic.
kafka-console-consumer –topic <topic name> \
–bootstrap-server <broker-host:port> \
–from-beginning
The plain consumers work with records of primitive Java types: String, Long, Double, Integer, etc. The default format expected for keys and values by the plain console consumer is the String type. We have to pass the fully qualified class names of the appropriate deserializers using the command line flags –key-deserializer and –value-deserializer if the keys or values are not strings. By default, the console consumer only prints the value component of the messages to the screen. If we want to see the keys as well, need to append the following flags:
![]()
kafka-console-consumer –topic \
–bootstrap-server <broker-host:port> \
–property print.key=true
–property key.separator=”:”
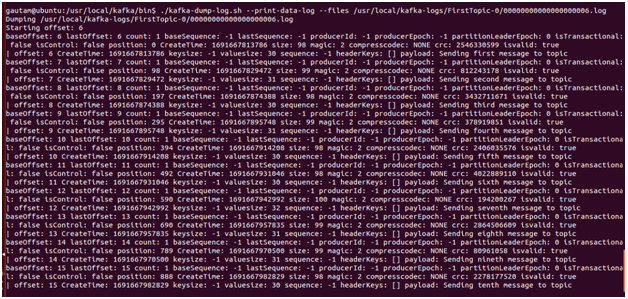
4. Kafka-dump-log.sh
The kafka-dump-log command is our buddy whether we just want to learn more about Kafka’s inner workings or we need to troubleshoot a problem and validate the content. By leveraging kafka-dump-log.sh, we can manually inspect the underlying logs of a topic.
kafka-dump-log \
–print-data-log \
–files ./usr/local/kafka-logs/FirstTopic-0/00000000000000000000.log
For a full list of options and a description of what each option does, run kafka-dump-log with the –help flag.
–print-data-log flag specifies to print the data in the log.
–files flag is required. This could also be a comma-separated list of files.
Each message’s key, payload (value), offset, and timestamp are easily visible in the dump log. Henceforth, lots of information that are available in the dump-log and can be extracted for troubleshooting, etc. Please note that in the captured screenshot, the keys and values for the topic “FirstTopic” are strings. To run the dump-log tool with key or value types other than strings, we’ll need to use either the –key-decoder-class or the –value-decoder-class flags.
5. Kafka-delete-records.sh
As we know that Kafka stores records for topics on disk and retains that data even once consumers have read it. Instead of being kept in a single large file, records are divided up into partition-specific segments where the offset order is continuous across segments for the same topic partition. As servers do not have infinite amounts of storage, using Kafka’s configuration settings we can control how much data can be retained based on time and size. In the server.properties file using log.retention.hours, which defaults to 168 hours (one week), the time configuration for controlling data retention can be achieved. And another property log.retention.bytes control how large segments can grow before they are eligible for deletion. By default, log.retention.bytes is commented in the server.properties file. Using log.segment.bytes, the maximum size of a log segment file is defined. The default value is 1073741824 and when this size is reached a new log segment will be created.
Typically we never want to go into the filesystem and manually delete files. In order to save space, we would prefer a controlled and supported method of deleting records from a topic. Using Kafka-delete-records.sh, we can delete data as desired. To execute Kafka-delete-records.sh on the terminal, two mandatory parameters are required.
a. –bootstrap-server: the broker(s) to connect to for bootstrapping
b. –offset-json-file: a JSON file containing the deletion settings
Here’s an example of the JSON file,
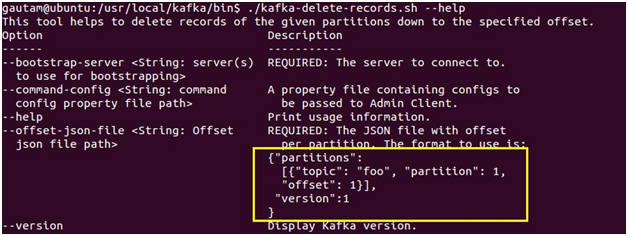
As we can see above, the format of the JSON is simple. It’s an array of JSON objects. Each JSON object has three properties:
– Topic: the topic to delete from
– Partition: the partition to delete from
– Offset: the offset we want the delete to start from, moving backward to lower offsets
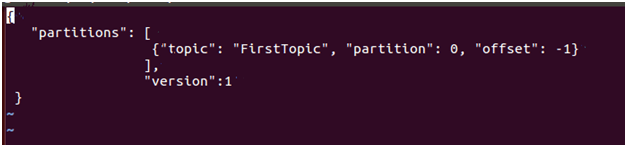
For this example, I’m reusing the same topic “FirstTopic” from the dump-log tool, so it’s a very simple JSON file. If we had more partitions or topics, we would simply expand on the JSON config file above. We could simply determine the beginning offset to begin the deletion process because the example topic “FirstTopic” only has 17 records. But in actual use, we’ll probably be unsure what offset to use. If we provide -1, then the offset of the high watermark is used, which means we will be deleting all the data currently in the topic. The high watermark is the highest available offset for consumption.
After executing the following command on the terminal, we can see the following
![]()
kafka-delete-records –bootstrap-server <broker-host:port> \
–offset-json-file offsets.json
The results of the command show that Kafka deleted all records from the topic partition FirstTopic-0. The low_watermark value of 17 indicates the lowest offset available to consumers. Because there were only 17 records in the “FirstTopic” topic. In nutshell, this script is helpful when we want to reset the consumer without stopping and restarting the Kafka broker cluster to flushing a Kafka topic if receives bad data. This script allows us to delete all the records from the beginning of a partition, until the specified offset.
Hope you have enjoyed this read. Please like and share if you feel this composition is valuable.

Written by
Gautam Goswami ![]()
Can be reached for real-time POC development and hands-on technical training at gautambangalore@gmail.com. Besides, to design, and develop just as help in any Hadoop/Big Data handling related task, Apache Kafka, Streaming Data, etc. Gautam is an advisor and furthermore an Educator as well. Before that, he filled in as Sr. Technical Architect in different technologies and business space across numerous nations.
He is energetic about sharing information through blogs and preparing workshops on different Big Data related innovations, systems, and related technologies.
{kind=link}