Complex event processing (CEP) is a highly effective and optimized mechanism that combines several sources of information and instantly determines and evaluates the relationships among events in real-time. It is a real-time data and event identification, processing, and analysis approach. By gathering and combining across various IoT sensor feeds, CEP has a transformative effect by collecting IoT sensor streams for real-time monitoring, analytics, and troubleshooting. CEP provides insight into what’s happening by continuously comparing incoming events to patterns. This enables us to operate proactively and effectively.
Although event stream processing (ESP) and CEP are often used interchangeably, they are not exactly the same. Traditional ESP applications typically handle a single stream of data that arrives in the correct time sequence. For instance, in algorithmic trading, an ESP application might analyze a stream of pricing data to decide whether to buy or sell a stock. However, ESP generally doesn’t account for event causality or hierarchies. This limitation led to the development of CEP, which is essentially a more advanced and sophisticated version of ESP.
For example, by combining distributed data obtained from lighting devices, various pressure gauges, smoke sensors, electrical consumptions, and other devices with real-time weather, date, and time information, the smart machinery in oil refineries can predict operational behavior and optimize the use of electricity, flow controls, etc.
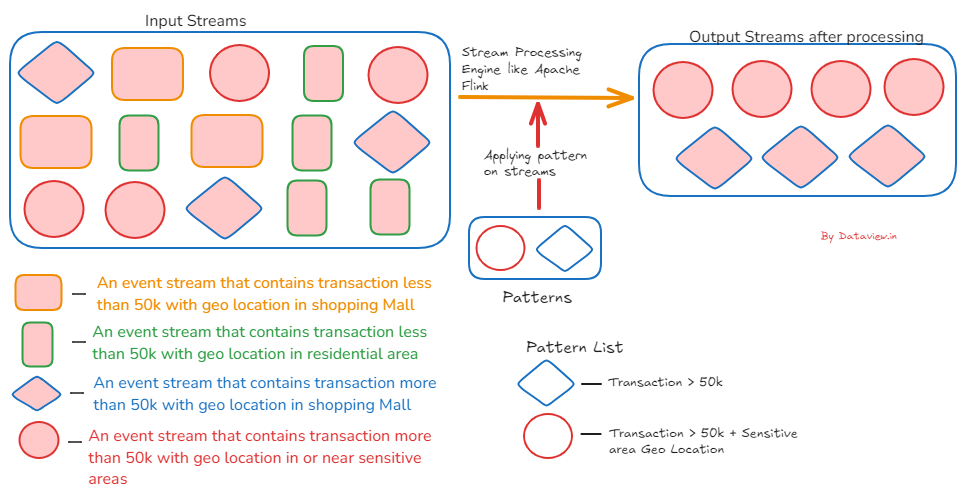
Extracting various inputs that are consolidated in the stream of events in the financial/banking sector by identifying fraudulent transactions against various patterns helps to take proactive, useful action. Let’s consider a single event in a UPI transaction (Unified Payments Interface is an instant real-time payment system developed by NPCI to facilitate inter-bank transactions through mobile phones.) and define one pattern to detect at what time from a particular location maximum transaction, say above 50K, is occurring within a specific time period.
{“timestamp”:”2024-08-20 22:39:20.866″,”upiID”:”9902480505@pnb”,”name”:”Brahma Gupta Sr.”,”note”:” “,”amount”:”2779.00″,”currency”:”INR”,”Latitude”:”22.5348319″,”Longitude”:”15.1863628″,”deviceOS”:”iOS”,”targetApp”:”GPAY”,”merchantTransactionId”:”3619d3c01f5ad14f521b320100d46318b9″,”merchantUserId”:”11185368866533@sbi”}
The defined or developed pattern will execute on each event stream, and when the specified conditions are met, it will extract and consolidate all relevant records. This allows us to determine the maximum transaction and identify the location from which it was initiated, whether it is a sensitive area, a residential area, or another type of location.
You can refer to the below diagram to understand better.
The CEP library built on top of Apache Flink is called FlinkCEP. It provides us with the ability to identify patterns in an infinite stream of occurrences, enabling us to extract meaningful information from the data streams. FlinkCEP is not a part of the Apache Flink binary distribution. You can read here if want to explore more.
Even though Apache Flink is designed for large-scale stream processing with comprehensive support for big data ecosystems, it doesn’t provide data persistence capabilities. Since Flink is positioned as a stream processing engine, the processed or output stream that comes out of Flink after computations with applied patterns needs to be sent to a distributed event streaming platform like Apache Kafka so that downstream applications can consume it for further analytics. Alternatively, it should be persisted in streaming databases like Apache Druid for querying and analysis.
On the other side, RisingWave is both a stream processing platform and a streaming database. Compared to Flink, Risingwave provides guaranteed consistency and completeness in stream processing. Besides, the overall component architecture can be simplified from all aspects like maintainability, scaling, troubleshooting, etc in CEP if we introduce RisingWave and omit Flink. As Flink does not have data persistence capabilities, RisingWave can be an excellent choice in CEP as it supports both.
In applying patterns in CEP, just as the FlinkCEP library in Flink provides this functionality, we can achieve similar results using materialized views in RisingWave. Materialized views in RisingWave are updated synchronously, ensuring that users always access the most up-to-date results. Even for complex queries involving joins and windowing, RisingWave efficiently manages synchronous processing to maintain the freshness of these views. After ingesting the complex event stream or multiple streams from various Apache Kafka topics into RisingWave (a streaming database), we can create materialized views on the ingested streams and query the results, similar to how the FlinkCEP library in Flink applies defined patterns to extract the required stream from the flowing complex events. You can read here (https://dataview.in/integrating-apache-kafka-with-risingwave/) to know how Apache Kafka can be integrated to ingest event streams into RisingWave. By considering the UPI transactions as explained above, I am going to explain how materialized views can be considered as patterns to filter out the records of transactions with more than 50 K and transactions carried out from sensitive areas with more than 50K.
Note:- To keep this article short, I have ignored details such as data types in the payload or each transaction event stream, the inclusion of a schema registry for data validation, etc. This provides a high-level overview, but many additional steps would be involved in an actual or real-time implementation.
To connect to the UPI transaction stream from the Apache Kafka’ topic, we need to create a source using the CREATE SOURCE command using the PostgreSQL client. Once the connection is established, RisingWave will be able to read or consume all the ingested events from Kafka’s topic continuously or in real-time.
CREATE SOURCE IF NOT EXISTS upi_transaction_stream (
timestamp timestamptz,
upi_id varchar,
name varchar,
… …….,
deviceOS varchar,
… ……,
amount integer,
merchantTransactionId varchar
Latitude number
Longitude number
….. ….
)
WITH (
connector=’kafka’,
topic=’UPIStream’,
properties.bootstrap.server=’192.168.10.150:9092′,
scan.startup.mode=’earliest’
) FORMAT PLAIN ENCODE JSON;
By creating a source, RisingWave has been connected to the Kafka topic. The next step is to create the materialized views that are equivalent to the two types of pattern to extract the event that has an amount of more than 50 K and the other one is an amount of more than 50K with transactions initiated from sensitive areas. Using the following SQL, we can create two materialized views to grab all existing transaction events from the already persisted events in RisingWave and continuously capture newly inserted events from the Kafka topic.
CREATE MATERIALIZED VIEW IF NOT EXISTS upi_transaction_more_than_50k AS
SELECT * FROM upi_transaction_stream where amount >= 50000;
CREATE MATERIALIZED VIEW IF NOT EXISTS upi_transaction_more_than_50k_sensitive_area AS
SELECT * FROM upi_transaction_stream where amount >= 50000 AND Latitude =”sensitive area co-ordinate” AND Longitude =”sensitive area co-ordinate”
Eventually by running a SELECT SQL query on the created materialized views{(SELECT * FROM upi_transaction_more_than_50k ) and (SELECT * FROM upi_transaction_more_than_50k_sensitive_area)}, we can continuously retrieve all transaction events and proceed to the next steps, such as initiating actions or making business decisions on UPI transactions by pushing them into downstream systems like email notifications, alerts, etc.
Although both RisingWave and Apache Flink provide stream processing capabilities, including CEP for real-time applications, using materialized views in RisingWave can simplify the architecture by eliminating the need for Apache Flink. This also minimizes the development effort required to define and insert patterns using the Pattern API in the FlinkCEP library. Materialized views in RisingWave are not refreshed at a preset interval or manually. They are automatically refreshed and incrementally computed whenever a new event is received. Upon the creation of a materialized view, the RisingWave engine searches for fresh (and pertinent) events. The computation overhead is negligible because it is limited to the recently received data.
Final Note:- CEP is extremely valuable in today’s data-driven world, where data is as essential as oil and is constantly growing. CEP addresses a key challenge in real-time processing by detecting patterns in data streams. While we can implement patterns on input streams using the FlinkCEP library, the materialized views in RisingWave offer a significant advantage by enabling users to query both materialized views and the internal states of stateful stream operators using PostgreSQL-style SQL. RisingWave is not just a stream processing platform but also a streaming database, whereas Flink is primarily a computation engine. RisingWave is simpler and easier to use, but Apache Flink, with its greater low-level control, has a steeper learning curve.
Ref:-
I hope you enjoyed reading this. If you found this article valuable, please consider liking and sharing it.
Can be reached for real-time POC development and hands-on technical training at gautambangalore@gmail.com. Besides, to design, develop just as help in any Hadoop/Big Data handling related task, Apache Kafka, Streaming Data etc. Gautam is a advisor and furthermore an Educator as well. Before that, he filled in as Sr. Technical Architect in different technologies and business space across numerous nations.
He is energetic about sharing information through blogs, preparing workshops on different Big Data related innovations, systems and related technologies.
Page: 1 2
Blockchain is an extremely data-driven technology because the primary function of a blockchain is to… Read More
AI agents now increasingly require real-time stream data processing as the environment involving the decision making… Read More
Hot data means the data currently being created, accessed, and queried at real-time or near… Read More
The data serialization format is a key factor when dealing with stream processing, as it… Read More
In today's AI-powered systems, real-time data is essential rather than optional. Real-time data streaming has… Read More
In the current fast-paced digital age, many data sources generate an unending flow of information,… Read More
{kind=link}
{kind=link}